使用 OTP 建構應用程式
我們已經看過如何使用通用伺服器、有限狀態機、事件處理程式和監管者。不過,我們還沒有確切地了解如何將它們一起使用來建構應用程式和工具。
Erlang 應用程式是一組相關的程式碼和程序。而 *OTP 應用程式* 則特別為其程序使用 OTP 行為,然後將它們包裝在一個非常特定的結構中,告訴虛擬機器如何設定所有內容,然後將其關閉。
所以在本章中,我們將使用 OTP 元件建構一個應用程式,但不是完整的 OTP 應用程式,因為我們現在不會做整個包裝。完整 OTP 應用程式的細節有點複雜,值得單獨一章(下一章)。本章將介紹如何實作程序池。這種程序池背後的想法是以通用方式管理和限制系統中執行的資源。
程序池

沒錯,池允許限制一次執行的程序數量。當執行中的工作者達到上限時,池也可以將工作排隊。然後,一旦資源釋放,就可以執行這些工作,或者只是告訴使用者他們無法做任何其他事情來進行封鎖。儘管真實世界的池與實際的程序池沒有任何相似之處,但仍有理由想要使用後者。其中一些可能包括
- 將伺服器限制為最多 N 個並行連線;
- 限制應用程式可以開啟的檔案數量;
- 透過允許某些子系統有更多資源,而另一些子系統有較少資源,來為發行的不同子系統提供不同的優先順序。例如,允許客戶端請求的程序比負責為管理階層產生報表的程序更多。
- 讓偶爾在突發情況下出現大量負載的應用程式,在整個生命週期中保持更穩定,方法是將任務排隊。
因此,我們的程序池應用程式將需要支援一些功能
- 啟動和停止應用程式
- 啟動和停止特定的程序池(所有池都位於程序池應用程式內)
- 在池中執行任務,如果池已滿,則告知您無法啟動
- 如果有空間,則在池中執行任務,否則讓呼叫程序等待,同時任務在佇列中。一旦任務可以執行,就釋放呼叫者。
- 在池中盡快非同步執行任務。如果沒有位置可用,則將其排隊,並在任何時候執行。
這些需求將有助於推動我們的程式設計。另外請記住,我們現在可以使用監管者。當然,我們想使用它們。問題是,如果它們在穩健性方面給予我們新的能力,它們也會對靈活性施加一定的限制。讓我們來探討一下。
洋蔥層理論

為了幫助我們自己設計一個使用監管者的應用程式,有必要了解哪些內容需要監管,以及如何監管。您會記得我們有不同的策略和不同的設定;這些設定將適用於具有不同錯誤的不同程式碼類型。可能會犯下各種錯誤!
新手甚至是經驗豐富的 Erlang 程式設計師通常難以處理的一件事是如何應對狀態的遺失。監管者會終止程序,狀態會遺失,真是悲哀。為了幫助解決這個問題,我們將識別不同種類的狀態
- 靜態狀態。這種型別可以輕鬆地從設定檔、另一個程序或重新啟動應用程式的監管者中取得。
- 動態狀態,由您可以重新計算的資料組成。這包括您必須從初始形式轉換為現在的形式才能取得的狀態
- 您無法重新計算的動態資料。這可能包括使用者輸入、即時資料、外部事件序列等。
現在,靜態資料比較容易處理。大多數時候,您可以直接從監管者取得。動態但可重新計算的資料也是如此。在這種情況下,您可能想要在 `init/1` 函式中,或在程式碼中的任何其他位置取得並計算它。
最具問題的狀態是您無法重新計算並且基本上只能希望不會遺失的動態資料。在某些情況下,您會將該資料推送到資料庫,儘管這並不總是好的選擇。
洋蔥層系統的想法是允許所有這些不同的狀態透過彼此隔離不同種類的程式碼來得到正確的保護。這是程序的隔離。
靜態狀態可以由監管者、啟動中的系統等處理。每次子程序終止時,監管者都會重新啟動它們,並可以為它們注入某種形式的靜態狀態,始終可用。因為大多數監管者定義本質上都是靜態的,所以您新增的每一層監管都充當一個盾牌,保護您的應用程式免受故障和狀態遺失的影響。
可以重新計算的動態狀態有很多可用的解決方案:從監管者傳送的靜態資料中建立它,從其他程序、資料庫、文字檔、目前環境或任何其他地方取回它。每次重新啟動時,應該都比較容易取回它。您有執行重新啟動工作的監管者這一事實就足以幫助您保持該狀態的存活。
動態且不可重新計算的狀態需要更周詳的方法。洋蔥層方法的真正本質在這裡形成。這個想法是,最重要的資料(或最難找回的資料)必須是保護程度最高的型別。實際上不允許您失敗的地方稱為應用程式的*錯誤核心*。

錯誤核心很可能是您想要比其他任何地方都更多使用 `try ... catch` 的地方,在其中處理異常情況至關重要。這是您希望沒有錯誤的地方。在那裡必須進行仔細的測試,尤其是在沒有辦法返回的情況下。您不希望在處理過程中遺失客戶的訂單,是吧?有些操作會被認為比其他操作更安全。因此,我們希望將重要資料保留在最安全的核心中,並將所有有點危險的東西都保留在核心之外。具體來說,這表示所有相關的操作都應該屬於同一個監管樹,而無關的操作應該保留在不同的樹中。在同一棵樹中,容易發生故障但並非至關重要的操作可以放在單獨的子樹中。盡可能只重新啟動樹中需要的部分。在設計我們實際的程序池監管樹時,我們會看到一個範例。
池的樹狀結構
那麼我們應該如何組織這些程序池呢?這裡有兩種思考方式。一種是告訴人們自下而上地設計(編寫所有個別元件,然後根據需要將它們組裝在一起),另一種是告訴我們自上而下地編寫(設計時假定所有部分都在那裡,然後建構它們)。這兩種方法在不同情況和您的個人風格中都同樣有效。為了讓事情容易理解,我們將在這裡自上而下地進行。
那麼我們的樹狀結構應該是什麼樣的呢?好的,我們的需求包括:能夠整體啟動池應用程式、擁有多個池,並且每個池都擁有可以排隊的多個工作者。這已經暗示了一些可能的設計約束。
每個池都需要一個 `gen_server`。伺服器的職責是維護池中工作者的數量計數器。為了方便起見,同一個伺服器也應該保留任務佇列。但是,應該由誰來負責監督每個工作者呢?伺服器本身嗎?
使用伺服器來執行此操作很有趣。畢竟,它需要追蹤程序以計算它們,而自行監管它們是一種很好的方法。此外,伺服器和程序都無法在不遺失所有其他程序狀態的情況下崩潰(否則伺服器在重新啟動後無法追蹤任務)。它也有一些缺點:伺服器有許多責任,可能被視為更脆弱,並且複製了現有、經過更好測試的模組的功能。
確保所有工作者都得到正確考慮的一個好方法是為它們使用一個監管者
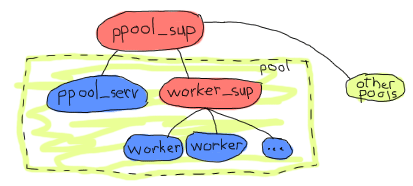
例如,上面的方法會為所有池設置一個監管者。每個池實際上都是一組池伺服器和一個工作者監管者。池伺服器知道其工作者監管者的存在,並要求它新增項目。鑑於新增子程序是一件非常動態的事情,目前尚無已知的限制,因此應使用 `simple_one_for_one` 監管者。
注意:選擇名稱 `ppool` 是因為 Erlang 標準程式庫已經有 `pool` 模組。另外,這是一個與池相關的糟糕雙關語。
這樣做的好處是,因為 `worker_sup` 監管者只需要追蹤單一類型的 OTP 工作者,因此保證每個池都只處理定義明確的某種類型的工作者,並且管理和重新啟動策略簡單且易於定義。這就是一個更好定義的錯誤核心的範例。如果我使用一個用於 Web 連線的 socket 池和另一個負責記錄檔的伺服器池,我就可以確保應用程式記錄檔部分中的不正確程式碼或混亂的權限不會淹沒負責 socket 的程序。如果記錄檔池崩潰太多次,它們將被關閉,而它們的監管者將停止。喔,等等!
沒錯。因為所有池都位於同一個監管者下,所以給定的池或伺服器在短時間內重新啟動太多次會導致所有其他池都關閉。這表示我們可能想要做的是新增一個監管層級。這也將使一次處理多個池更加簡單,所以讓我們說以下將是我們的應用程式架構
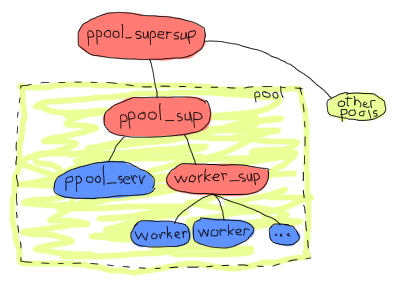
這樣更有意義。從洋蔥層的角度來看,所有池都是獨立的,工作者彼此獨立,而 `ppool_serv` 伺服器將與所有工作者隔離。這對架構來說已經足夠了,我們需要的一切似乎都在那裡。我們可以開始實作,同樣地,由上而下。
實作監管者
我們可以從最上層的監管者開始,也就是 ppool_supersup。這個監管者的任務很簡單,就是根據需要啟動池的監管者。我們會給它一些函式:start_link/0,用來啟動整個應用程式;stop/0,用來停止應用程式;start_pool/3,用來建立特定的池;以及 stop_pool/1,做相反的事情。我們也不能忘記 init/1,它是監管者行為唯一需要的 callback 函式。
-module(ppool_supersup).
-behaviour(supervisor).
-export([start_link/0, stop/0, start_pool/3, stop_pool/1]).
-export([init/1]).
start_link() ->
supervisor:start_link({local, ppool}, ?MODULE, []).
這裡我們將最上層的進程池監管者命名為 ppool(這解釋了為什麼使用 {local, Name},這是 OTP 中在節點上註冊 gen_* 進程的慣例;還有一個用於分散式註冊)。這是因為我們知道每個 Erlang 節點只會有一個 ppool,我們可以給它一個名稱而不用擔心衝突。幸運的是,可以使用相同的名稱來停止整組池。
%% technically, a supervisor can not be killed in an easy way.
%% Let's do it brutally!
stop() ->
case whereis(ppool) of
P when is_pid(P) ->
exit(P, kill);
_ -> ok
end.
如同程式碼中的註解所解釋的,我們無法優雅地終止監管者。原因是 OTP 框架為所有監管者提供了完善的關閉程序,但我們現在無法從這裡使用它。我們將在下一章看到如何做到這一點,但目前,粗暴地終止監管者是我們能做的最好的方法。
最上層的監管者到底是什麼?嗯,它的唯一任務就是將池保存在記憶體中並監管它們。在這種情況下,它將是一個沒有子進程的監管者。
init([]) ->
MaxRestart = 6,
MaxTime = 3600,
{ok, {{one_for_one, MaxRestart, MaxTime}, []}}.
現在我們可以專注於啟動每個單獨池的監管者,並將它們附加到 ppool。根據我們最初的需求,我們可以確定我們需要兩個參數:池將接受的工作者數量,以及工作者監管者需要啟動每個工作者的 {M,F,A} 元組。為了方便起見,我們還會添加一個名稱。然後,當我們啟動池時,將此 childspec 傳遞給進程池的監管者。
start_pool(Name, Limit, MFA) ->
ChildSpec = {Name,
{ppool_sup, start_link, [Name, Limit, MFA]},
permanent, 10500, supervisor, [ppool_sup]},
supervisor:start_child(ppool, ChildSpec).
您可以看到每個池監管者都被要求是永久性的,並具有所需的參數(請注意我們是如何將程式設計師提交的資料轉換為靜態資料的)。池的名稱既傳遞給監管者,又用作 child specification 中的識別符。還有一個最長關閉時間為 10500。沒有簡單的方法可以選擇這個值。只需確保它足夠大,以便所有子進程都有時間停止。根據您的需要調整它們並測試和調整自己。如果您只是不知道,也可以嘗試 infinity 選項。
要停止池,我們需要要求 ppool 超級監管者(supersup!)殺死其匹配的子進程。
stop_pool(Name) ->
supervisor:terminate_child(ppool, Name),
supervisor:delete_child(ppool, Name).
這是可能的,因為我們將池的 Name 作為 childspec 識別符。太棒了!我們現在可以專注於每個池的直接監管者!
每個 ppool_sup 將負責池伺服器和工作者監管者。
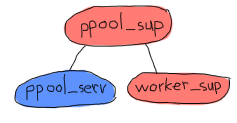
您可以看到這裡有趣的事情嗎?ppool_serv 進程應該能夠聯繫 worker_sup 進程。如果我們要讓它們由同一個監管者同時啟動,我們將無法讓 ppool_serv 知道 worker_sup,除非我們使用 supervisor:which_children/1(這會對時序敏感且有些冒險)進行一些技巧,或者為 ppool_serv 進程(以便使用者可以呼叫它)和監管者都命名。現在我們不想給監管者命名,因為
- 使用者不需要直接呼叫它們
- 我們需要動態生成原子,這讓我感到不安
- 有一個更好的方法。
方法基本上是讓池伺服器動態地將工作者監管者附加到其 ppool_sup。如果這很模糊,您很快就會明白。現在我們只啟動伺服器。
-module(ppool_sup).
-export([start_link/3, init/1]).
-behaviour(supervisor).
start_link(Name, Limit, MFA) ->
supervisor:start_link(?MODULE, {Name, Limit, MFA}).
init({Name, Limit, MFA}) ->
MaxRestart = 1,
MaxTime = 3600,
{ok, {{one_for_all, MaxRestart, MaxTime},
[{serv,
{ppool_serv, start_link, [Name, Limit, self(), MFA]},
permanent,
5000, % Shutdown time
worker,
[ppool_serv]}]}}.
就是這樣了。請注意,Name 會與 self()(監管者自己的 pid)一起傳遞給伺服器。這將讓伺服器呼叫來產生工作者監管者;MFA 變數將在該呼叫中使用,讓 simple_one_for_one 監管者知道要執行哪種類型的工作者。
我們將了解伺服器如何處理一切,但現在我們將通過編寫 ppool_worker_sup 來完成所有應用程式的監管者的編寫,它負責所有工作者。
-module(ppool_worker_sup).
-export([start_link/1, init/1]).
-behaviour(supervisor).
start_link(MFA = {_,_,_}) ->
supervisor:start_link(?MODULE, MFA).
init({M,F,A}) ->
MaxRestart = 5,
MaxTime = 3600,
{ok, {{simple_one_for_one, MaxRestart, MaxTime},
[{ppool_worker,
{M,F,A},
temporary, 5000, worker, [M]}]}}.
那裡的東西很簡單。我們選擇了 simple_one_for_one,因為工作者可以大量快速地添加,而且我們想限制它們的類型。所有工作者都是暫時的,並且因為我們使用 {M,F,A} 元組來啟動工作者,所以我們可以在那裡使用任何類型的 OTP 行為。

讓工作者成為暫時的有兩個原因。首先,我們不能確定它們在失敗時是否需要重新啟動,或者它們需要哪種重新啟動策略。其次,只有在工作者的建立者可以訪問工作者的 pid 時,池可能才有用,這取決於使用情況。為了以任何安全和簡單的方式工作,我們不能隨意重新啟動工作者而不追蹤其建立者並向其發送通知。這會讓事情變得相當複雜,只是為了獲取 pid。當然,您可以自由編寫自己的 ppool_worker_sup,它不會傳回 pid 而是重新啟動它們。該設計本身沒有任何錯誤。
處理工作者
池伺服器是應用程式中最複雜的部分,所有巧妙的業務邏輯都在這裡發生。以下是我們必須支援的操作的提醒。
- 在池中執行任務,如果池已滿,則告知您無法啟動
- 如果還有位置,則在池中執行任務,否則讓呼叫進程在任務在佇列中等待時保持等待,直到可以執行該任務。
- 在池中盡快非同步執行任務。如果沒有位置可用,則將其排隊,並在任何時候執行。
第一個將由名為 run/2 的函式完成,第二個將由 sync_queue/2 完成,最後一個將由 async_queue/2 完成。
-module(ppool_serv).
-behaviour(gen_server).
-export([start/4, start_link/4, run/2, sync_queue/2, async_queue/2, stop/1]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
start(Name, Limit, Sup, MFA) when is_atom(Name), is_integer(Limit) ->
gen_server:start({local, Name}, ?MODULE, {Limit, MFA, Sup}, []).
start_link(Name, Limit, Sup, MFA) when is_atom(Name), is_integer(Limit) ->
gen_server:start_link({local, Name}, ?MODULE, {Limit, MFA, Sup}, []).
run(Name, Args) ->
gen_server:call(Name, {run, Args}).
sync_queue(Name, Args) ->
gen_server:call(Name, {sync, Args}, infinity).
async_queue(Name, Args) ->
gen_server:cast(Name, {async, Args}).
stop(Name) ->
gen_server:call(Name, stop).
對於 start/4 和 start_link/4,Args 將是要傳遞給傳遞到監管者的 {M,F,A} 三元組的 A 部分的附加參數。請注意,對於同步佇列,我將等待時間設定為 infinity。
如前所述,我們必須從伺服器內部啟動監管者。如果您在我們進行時新增程式碼,您可能需要包含一個空的 gen_server 範本(或使用 完整檔案)來跟隨,因為我們將按功能而不是從頭到尾讀取伺服器來完成事情。
我們做的第一件事是處理監管者的建立。如果您記得上一章關於 動態監管 的內容,在我們需要新增少量子進程的情況下,我們不需要 simple_one_for_one,因此 supervisor:start_child/2 應該可以解決問題。我們首先定義工作者監管者的 child specification。
%% The friendly supervisor is started dynamically!
-define(SPEC(MFA),
{worker_sup,
{ppool_worker_sup, start_link, [MFA]},
temporary,
10000,
supervisor,
[ppool_worker_sup]}).
沒有什麼特別的。然後我們可以定義伺服器的內部狀態。我們知道我們必須追蹤一些資料:可以執行的進程數、監管者的 pid 以及所有工作的佇列。為了知道工作者何時完成執行並從佇列中取出一個來啟動它,我們需要從伺服器追蹤每個工作者。這樣做的合理方法是使用監視器,因此我們還會將 refs 欄位新增到我們的狀態記錄中,以便將所有監視器參照保存在記憶體中。
-record(state, {limit=0,
sup,
refs,
queue=queue:new()}).
準備就緒後,我們可以開始實作 init 函式。自然而然地嘗試以下方法:
init({Limit, MFA, Sup}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
link(Pid),
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
然後開始。但是,此程式碼是錯誤的。gen_* 行為的工作方式是,產生該行為的進程會等待 init/1 函式傳回,然後再繼續其處理。這表示通過在其中呼叫 supervisor:start_child/2,我們建立以下死鎖:
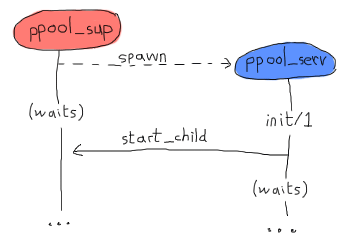
兩個進程將繼續等待對方,直到崩潰。解決此問題最乾淨的方法是建立一個特殊的訊息,伺服器將該訊息傳送給自己,以便在伺服器傳回(且池監管者已變為空閒)後,立即在 handle_info/2 中處理它。
init({Limit, MFA, Sup}) ->
%% We need to find the Pid of the worker supervisor from here,
%% but alas, this would be calling the supervisor while it waits for us!
self() ! {start_worker_supervisor, Sup, MFA},
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
這個更乾淨。然後我們可以轉到 handle_info/2 函式並新增以下子句:
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
link(Pid),
{noreply, S#state{sup=Pid}};
handle_info(Msg, State) ->
io:format("Unknown msg: ~p~n", [Msg]),
{noreply, State}.
第一個子句在這裡很有趣。我們找到我們自己傳送的訊息(這必然是收到的第一個訊息),要求池監管者新增工作者監管者,追蹤此 Pid,然後就完成了!我們的樹現在已完全初始化。呼。您可以嘗試編譯所有內容,以確保到目前為止沒有出現任何錯誤。不幸的是,我們仍然無法測試應用程式,因為缺少太多東西。
注意:如果您不喜歡在執行之前建構整個應用程式的想法,請不要擔心。這樣做是為了展示對整個事物的更清晰的推理。雖然我確實有一個總體設計(與我之前說明的一樣),但我開始以一點測試驅動的方式編寫這個池應用程式,並 在這裡和那裡進行了一些測試,並進行了一堆重構,以使所有內容都達到可運作的狀態。
很少有 Erlang 程式設計師(就像大多數其他語言的程式設計師一樣)能夠在第一次嘗試時就產生可供生產的程式碼,並且作者沒有範例看起來那麼聰明。
好吧,所以我們已經解決了這個問題。現在我們將處理 run/2 函式。這是一個帶有 {run, Args} 形式訊息的同步呼叫,其工作方式如下:
handle_call({run, Args}, _From, S = #state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{reply, {ok,Pid}, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_call({run, _Args}, _From, S=#state{limit=N}) when N =< 0 ->
{reply, noalloc, S};
一個很長的函式標頭,但我們可以看見大部分管理發生在那裡。只要池中還有位置(原始限制 N 由最初新增池的程式設計師決定),我們就接受啟動工作者。然後我們設定一個監視器來知道它何時完成,將所有這些儲存在我們的狀態中,遞減計數器,然後就開始了。
如果沒有可用的空間,我們只需回覆 noalloc。
對 sync_queue/2 的呼叫將提供非常相似的實作:
handle_call({sync, Args}, _From, S = #state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{reply, {ok,Pid}, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_call({sync, Args}, From, S = #state{queue=Q}) ->
{noreply, S#state{queue=queue:in({From, Args}, Q)}};
如果還有更多工作者的空間,那麼第一個子句將執行與我們對 run/2 所做的完全相同的事情。區別在於沒有工作者可以執行的情況。與上次回覆 noalloc 不同,這次沒有回覆呼叫者,而是保留 From 資訊並將其放入佇列中,以便在有執行工作者的空間時再執行。我們很快就會看到如何將它們從佇列中取出並處理它們,但現在,我們將使用以下子句完成 handle_call/3 回呼:
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Msg, _From, State) ->
{noreply, State}.
這些子句處理未知情況和 stop/1 呼叫。我們現在可以專注於讓 async_queue/2 工作。因為 async_queue/2 基本上不關心工作者何時執行,並且完全不希望收到回覆,所以決定將其設為 cast 而不是 call。您會發現它的邏輯與先前的兩個選項非常相似:
handle_cast({async, Args}, S=#state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{noreply, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_cast({async, Args}, S=#state{limit=N, queue=Q}) when N =< 0 ->
{noreply, S#state{queue=queue:in(Args,Q)}};
%% Not going to explain this one!
handle_cast(_Msg, State) ->
{noreply, State}.
同樣,除了不回覆之外,唯一的重大區別在於,當沒有工作者的位置時,它會放入佇列中。但是,這次我們沒有 From 資訊,只是在沒有它的情況下將其傳送到佇列中;在這種情況下,限制不會改變。
我們何時知道該從佇列中取出東西?嗯,我們到處都設定了監視器,並將它們的參照儲存在 gb_sets 中。每當工作者關閉時,我們都會收到通知。讓我們從那裡開始:
handle_info({'DOWN', Ref, process, _Pid, _}, S = #state{refs=Refs}) ->
io:format("received down msg~n"),
case gb_sets:is_element(Ref, Refs) of
true ->
handle_down_worker(Ref, S);
false -> %% Not our responsibility
{noreply, S}
end;
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
...
handle_info(Msg, State) ->
...
我們在程式碼片段中所做的是確保我們收到的 'DOWN' 訊息來自工作者。如果它不是來自工作者(這會很令人驚訝),我們就忽略它。但是,如果該訊息確實是我們想要的訊息,我們會呼叫名為 handle_down_worker/2 的函式:
handle_down_worker(Ref, S = #state{limit=L, sup=Sup, refs=Refs}) ->
case queue:out(S#state.queue) of
{{value, {From, Args}}, Q} ->
{ok, Pid} = supervisor:start_child(Sup, Args),
NewRef = erlang:monitor(process, Pid),
NewRefs = gb_sets:insert(NewRef, gb_sets:delete(Ref,Refs)),
gen_server:reply(From, {ok, Pid}),
{noreply, S#state{refs=NewRefs, queue=Q}};
{{value, Args}, Q} ->
{ok, Pid} = supervisor:start_child(Sup, Args),
NewRef = erlang:monitor(process, Pid),
NewRefs = gb_sets:insert(NewRef, gb_sets:delete(Ref,Refs)),
{noreply, S#state{refs=NewRefs, queue=Q}};
{empty, _} ->
{noreply, S#state{limit=L+1, refs=gb_sets:delete(Ref,Refs)}}
end.
這相當複雜。因為我們的 worker 已經結束,我們可以查看佇列中下一個要執行的項目。我們藉由從佇列中彈出一個元素來做到這一點,並查看結果是什麼。如果佇列中至少有一個元素,它的格式會是 {{value, Item}, NewQueue}。如果佇列是空的,它會回傳 {empty, SameQueue}。此外,我們知道當我們有值 {From, Args} 時,表示它來自 sync_queue/2,否則表示它來自 async_queue/2。
佇列中有任務的兩種情況行為大致相同:一個新的 worker 被附加到 worker supervisor,舊的 worker 監控器參考被移除,並替換為新的 worker 監控器參考。唯一的不同之處在於同步呼叫的情況下,我們會發送手動回覆,而另一個則保持靜默。大概就是這樣。
如果佇列是空的,我們只需要將 worker 限制增加一即可。
最後要做的就是加入標準的 OTP 回呼函式。
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
這樣就完成了,我們的 pool 已經準備好使用了!不過,這是一個非常不友善的 pool。我們需要使用的所有函式散落在各處。有些在 ppool_supersup 中,有些在 ppool_serv 中。此外,模組名稱也沒有理由那麼長。為了讓事情變得更好,請將以下 API 模組(只是將呼叫抽象化)加入到應用程式的目錄中。
%%% API module for the pool
-module(ppool).
-export([start_link/0, stop/0, start_pool/3,
run/2, sync_queue/2, async_queue/2, stop_pool/1]).
start_link() ->
ppool_supersup:start_link().
stop() ->
ppool_supersup:stop().
start_pool(Name, Limit, {M,F,A}) ->
ppool_supersup:start_pool(Name, Limit, {M,F,A}).
stop_pool(Name) ->
ppool_supersup:stop_pool(Name).
run(Name, Args) ->
ppool_serv:run(Name, Args).
async_queue(Name, Args) ->
ppool_serv:async_queue(Name, Args).
sync_queue(Name, Args) ->
ppool_serv:sync_queue(Name, Args).
現在我們真的完成了!
注意:您會注意到我們的程序池沒有限制可以儲存在佇列中的項目數量。在某些情況下,真正的伺服器應用程式需要對可以排隊的數量設定上限,以避免在使用過多記憶體時崩潰,儘管如果只使用具有固定數量呼叫者的 run/2 和 sync_queue/2,就可以避開這個問題(如果所有內容生產者都卡在等待池中的可用空間,他們一開始就會停止產生這麼多內容)。
將佇列大小限制加入是留給讀者的練習,但別擔心,因為這相對簡單;您需要將一個新的參數傳遞給伺服器上的所有函式,然後伺服器會在任何排隊之前檢查限制。
此外,為了控制系統的負載,您有時會想要使用同步呼叫,在更接近來源的地方設定限制。當系統被生產者以比消費者更快的速度淹沒時,同步呼叫可以阻止傳入的查詢;這通常有助於使其比自由放任的負載更具反應性。
撰寫 Worker
看看我,我一直在說謊!這個 pool 並沒有真正準備好使用。我們目前沒有 worker。我忘記了。這很可惜,因為我們都知道在關於撰寫並行應用程式的章節中,我們為自己編寫了一個不錯的任務提醒。這顯然對我來說還不夠,所以對於這個,我要讓我們撰寫一個嘮叨鬼。
基本上,每個任務都會有一個 worker,而這個 worker 會不斷發送重複的訊息來煩擾我們,直到指定的截止時間。它可以接收:
- 一個嘮叨的延遲時間,
- 一個地址 (pid),表示訊息應該發送到哪裡,
- 一個要發送到進程信箱的嘮叨訊息,包含嘮叨鬼自己的 pid 以便能夠呼叫…
- …一個停止函式,表示任務已完成,嘮叨鬼可以停止嘮叨。
開始吧
%% demo module, a nagger for tasks,
%% because the previous one wasn't good enough
-module(ppool_nagger).
-behaviour(gen_server).
-export([start_link/4, stop/1]).
-export([init/1, handle_call/3, handle_cast/2,
handle_info/2, code_change/3, terminate/2]).
start_link(Task, Delay, Max, SendTo) ->
gen_server:start_link(?MODULE, {Task, Delay, Max, SendTo} , []).
stop(Pid) ->
gen_server:call(Pid, stop).
是的,我們將要使用另一個 gen_server。您會發現人們一直都在使用它們,即使有時不太適合!重要的是要記住,我們的 pool 可以接受任何符合 OTP 規範的程序,而不僅僅是 gen_servers。
init({Task, Delay, Max, SendTo}) ->
{ok, {Task, Delay, Max, SendTo}, Delay}.
這只是獲取基本資料並轉發它。再次強調,Task 是要作為訊息發送的內容,Delay 是每次發送之間的時間間隔,Max 是要發送的次數,而 SendTo 是一個 pid 或一個名稱,訊息會發送到那裡。請注意,Delay 作為元組的第三個元素傳遞,這表示 Delay 毫秒後,timeout 將會發送到 handle_info/2。
根據我們上面的 API,大部分伺服器程式碼都很簡單明瞭
%%% OTP Callbacks
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Msg, _From, State) ->
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info(timeout, {Task, Delay, Max, SendTo}) ->
SendTo ! {self(), Task},
if Max =:= infinity ->
{noreply, {Task, Delay, Max, SendTo}, Delay};
Max =< 1 ->
{stop, normal, {Task, Delay, 0, SendTo}};
Max > 1 ->
{noreply, {Task, Delay, Max-1, SendTo}, Delay}
end.
%% We cannot use handle_info below: if that ever happens,
%% we cancel the timeouts (Delay) and basically zombify
%% the entire process. It's better to crash in this case.
%% handle_info(_Msg, State) ->
%% {noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) -> ok.
這裡唯一有點複雜的部分在於 handle_info/2 函式。正如在gen_server 章節中所見,每次達到逾時(在這裡,是經過 Delay 毫秒後),timeout 訊息會被發送到該程序。根據這個,我們檢查已經發送了多少個嘮叨訊息,以了解我們是否必須發送更多訊息或只是退出。有了這個 worker 完成,我們實際上可以嘗試這個程序池!
執行 Pool 執行
我們現在可以玩這個 pool,編譯所有檔案並啟動頂級的 supervisor 本身
$ erlc *.erl
$ erl
Erlang R14B02 (erts-5.8.3) [source] [64-bit] [smp:4:4] [rq:4] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V5.8.3 (abort with ^G)
1> ppool:start_link().
{ok,<0.33.0>}
從這一點開始,我們可以嘗試嘮叨鬼作為 pool 的一些不同功能
2> ppool:start_pool(nagger, 2, {ppool_nagger, start_link, []}).
{ok,<0.35.0>}
3> ppool:run(nagger, ["finish the chapter!", 10000, 10, self()]).
{ok,<0.39.0>}
4> ppool:run(nagger, ["Watch a good movie", 10000, 10, self()]).
{ok,<0.41.0>}
5> flush().
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.39.0>,"finish the chapter!"}
ok
6> ppool:run(nagger, ["clean up a bit", 10000, 10, self()]).
noalloc
7> flush().
Shell got {<0.41.0>,"Watch a good movie"}
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.41.0>,"Watch a good movie"}
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.41.0>,"Watch a good movie"}
...
對於同步的非佇列執行,一切似乎都運作良好。pool 已啟動,任務已加入,訊息已發送到正確的目的地。當我們嘗試執行比允許的任務更多的任務時,分配被拒絕。沒時間清理,抱歉!其他的執行仍然順利。
注意:ppool 是以 start_link/0 啟動的。如果在 shell 中發生任何錯誤,您會關閉整個 pool,並且必須重新開始。這個問題將在下一章中解決。
注意:當然,更乾淨的嘮叨鬼可能會呼叫一個事件管理器,用來將訊息正確轉發到所有適當的媒體。不過,實際上,許多產品、協議和函式庫都容易發生變化,我一直很討厭一旦外部依賴項過時就無法閱讀的書籍。因此,我傾向於讓所有外部依賴項保持在較低的水平,如果不是完全沒有的話。
我們可以嘗試排隊功能(非同步),只是看看
8> ppool:async_queue(nagger, ["Pay the bills", 30000, 1, self()]).
ok
9> ppool:async_queue(nagger, ["Take a shower", 30000, 1, self()]).
ok
10> ppool:async_queue(nagger, ["Plant a tree", 30000, 1, self()]).
ok
<wait a bit>
received down msg
received down msg
11> flush().
Shell got {<0.70.0>,"Pay the bills"}
Shell got {<0.72.0>,"Take a shower"}
<wait some more>
received down msg
12> flush().
Shell got {<0.74.0>,"Plant a tree"}
ok
太棒了!因此排隊運作正常。這裡的日誌並沒有以非常清晰的方式顯示所有內容,但那裡發生的情況是,前兩個嘮叨鬼會儘快執行。然後,達到 worker 限制,我們需要將第三個排隊(種樹)。當支付帳單的嘮叨鬼完成時,樹木嘮叨鬼會被排程並稍後發送訊息。
同步的行為會有不同
13> ppool:sync_queue(nagger, ["Pet a dog", 20000, 1, self()]).
{ok,<0.108.0>}
14> ppool:sync_queue(nagger, ["Make some noise", 20000, 1, self()]).
{ok,<0.110.0>}
15> ppool:sync_queue(nagger, ["Chase a tornado", 20000, 1, self()]).
received down msg
{ok,<0.112.0>}
received down msg
16> flush().
Shell got {<0.108.0>,"Pet a dog"}
Shell got {<0.110.0>,"Make some noise"}
ok
received down msg
17> flush().
Shell got {<0.112.0>,"Chase a tornado"}
ok
再次強調,日誌不像您親自嘗試時那麼清晰(我鼓勵您這樣做)。基本事件順序是將兩個 worker 加入到 pool 中。它們尚未完成執行,當我們嘗試加入第三個時,shell 會被鎖定,直到 ppool_serv(在進程名稱 nagger 下)收到 worker 的 down 訊息 (received down msg)。在此之後,我們對 sync_queue/2 的呼叫才能回傳,並給我們全新的 worker 的 pid。
我們現在可以完全擺脫這個 pool
18> ppool:stop_pool(nagger). ok 19> ppool:stop(). ** exception exit: killed
如果您決定直接呼叫 ppool:stop(),所有的 pool 都會終止,但您會收到一堆錯誤訊息。這是因為我們粗暴地殺死了 ppool_supersup 程序,而不是正確地關閉它(這反過來會導致所有子 pool 崩潰),但是下一章將介紹如何乾淨地做到這一點。
清理 Pool
回顧一切,我們已經設法撰寫了一個程序池,以某種簡單的方式進行一些資源分配。一切都可以並行處理,可以受到限制,並且可以從其他程序呼叫。您的應用程式中崩潰的部分,可以在 supervisor 的幫助下,被透明地替換,而不會破壞整個應用程式。一旦 pool 應用程式準備就緒,我們甚至可以用很少的程式碼重寫了我們提醒應用程式中相當大的一部分。
單一電腦的故障隔離已經被考慮在內,並行性已經被處理,現在我們有足夠的架構模塊來撰寫一些相當穩固的伺服器端軟體,即使我們還沒有真正看到從 shell 執行它們的好方法...
下一章將展示如何將 ppool 應用程式打包成真正的 OTP 應用程式,準備好被其他產品發布和使用。到目前為止,我們還沒有看到 OTP 的所有進階功能,但我可以告訴您,您現在已經達到可以理解大多數關於 OTP 和 Erlang(至少是非分散式部分)的中級到早期進階討論的水平。這很棒!