以函數式解決問題
聽起來我們已經準備好用我們所學的 Erlang 知識來做一些實際的事情了。這裡不會展示任何新的東西,而是如何應用我們之前看過的一些內容。本章中的問題取自 Miran 的 Learn You a Haskell。我決定採用相同的解決方案,以便好奇的讀者可以隨意比較 Erlang 和 Haskell 中的解決方案。如果您這樣做,您可能會發現對於語法如此不同的兩種語言,最終結果非常相似。這是因為一旦您了解了函數式概念,它們就相對容易轉移到其他函數式語言。
反向波蘭表示法計算機
大多數人都學會了使用數字之間的運算符來編寫算術表達式 ((2 + 2) / 5)。這是大多數計算機允許您輸入數學表達式的方式,也可能是您在學校學習計數時所教的表示法。這種表示法的缺點是需要您了解運算符優先順序:乘法和除法比加法和減法更重要(具有更高的優先順序)。
還有一種表示法,稱為前綴表示法或波蘭表示法,其中運算符位於運算元之前。在這種表示法下,(2 + 2) / 5 將變成 (/ (+ 2 2) 5)。如果我們決定說 + 和 / 總是接受兩個參數,那麼 (/ (+ 2 2) 5) 可以簡單地寫成 / + 2 2 5。
但是,我們將重點關注反向波蘭表示法(或簡稱 RPN),它是前綴表示法的相反:運算符位於運算元之後。上面相同的 RPN 範例將寫成 2 2 + 5 /。其他範例表達式可以是 9 * 5 + 7 或 10 * 2 * (3 + 4) / 2,它們分別轉換為 9 5 * 7 + 和 10 2 * 3 4 + * 2 /。這種表示法在早期的計算機模型中大量使用,因為它只需要很少的記憶體即可使用。事實上,有些人仍然隨身攜帶 RPN 計算機。我們將編寫一個這樣的計算機。
首先,了解如何讀取 RPN 表達式可能不錯。一種方法是逐一找出運算符,然後按元數將它們與其運算元重新組合
10 4 3 + 2 * - 10 (4 3 +) 2 * - 10 ((4 3 +) 2 *) - (10 ((4 3 +) 2 *) -) (10 (7 2 *) -) (10 14 -) -4
但是,在電腦或計算機的環境中,一種更簡單的方法是在看到所有運算元時建立一個堆疊。以數學表達式 10 4 3 + 2 * - 為例,我們看到的第一個運算元是 10。我們將其新增到堆疊中。然後是 4,所以我們也將其推入堆疊頂部。第三個位置,我們有 3;我們也將其推入堆疊。我們的堆疊現在應該看起來像這樣
![A stack showing the values [3 4 10]](https://learnyousomeerlang.dev.org.tw/static/img/stack1.png)
要解析的下一個字元是 +。它是一個元數為 2 的函數。為了使用它,我們需要餵給它兩個運算元,它們將從堆疊中取出
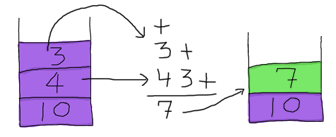
因此,我們取出 7 並將其推回堆疊頂部(哎呀,我們不想讓這些骯髒的數字到處漂浮!)堆疊現在是 [7,10],而表達式中剩下的部分是 2 * -。我們可以取出 2 並將其推到堆疊頂部。然後我們看到 *,它需要兩個運算元才能工作。同樣,我們從堆疊中取出它們
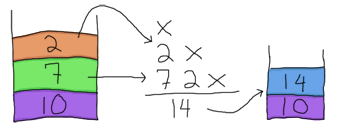
並將 14 推回堆疊頂部。剩下的只有 -,它也需要兩個運算元。天啊,太幸運了!我們的堆疊中還剩下兩個運算元。使用它們!
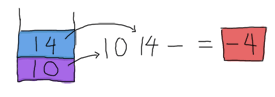
因此,我們得到了結果。這種基於堆疊的方法相對來說很可靠,而且在開始計算結果之前只需要做少量解析,這就解釋了為什麼老式計算機使用這種方法是個好主意。使用 RPN 還有其他原因,但這有點超出本指南的範圍,因此您可能想點擊維基百科文章。
一旦我們完成了複雜的事情,用 Erlang 編寫這個解決方案並不太難。事實證明,困難的部分是弄清楚為了獲得最終結果需要完成哪些步驟,而我們剛剛已經做到了。太棒了。打開一個名為 calc.erl 的檔案。
首先要擔心的是我們將如何表示數學表達式。為了簡化,我們可能會將它們作為字串輸入:"10 4 3 + 2 * -"。這個字串有空白,這不是我們問題解決過程的一部分,但為了使用簡單的語法分析器是必要的。那麼,可用的將是一個形式為 ["10","4","3","+","2","*","-"] 的詞條列表,經過語法分析器後。事實證明,函數 string:tokens/2 就是做這件事的
1> string:tokens("10 4 3 + 2 * -", " ").
["10","4","3","+","2","*","-"]
這將是我們表達式的一個很好的表示形式。下一個要定義的部分是堆疊。我們將如何做到這一點?您可能已經注意到 Erlang 的列表很像堆疊。在 [Head|Tail] 中使用 cons (|) 運算符實際上與將 Head 推入堆疊頂部(在本例中為 Tail)的行為相同。使用列表作為堆疊就足夠了。
要讀取表達式,我們只需要像手工解決問題時那樣做即可。從表達式中讀取每個值,如果是數字,則將其放入堆疊中。如果是函數,則從堆疊中彈出它所需的所有值,然後將結果推回。概括來說,我們需要做的只是將整個表達式作為循環遍歷一次,並累積結果。這聽起來像是 fold 的完美工作!
我們需要為 lists:foldl/3 將應用於表達式的每個運算符和運算元的函數做計劃。這個函數,由於它會在 fold 中執行,因此需要接受兩個參數:第一個參數是要處理的表達式元素,第二個參數是堆疊。
我們可以開始在 calc.erl 檔案中編寫我們的程式碼。我們將編寫負責所有循環的函數,以及刪除表達式中的空格的函數
-module(calc).
-export([rpn/1]).
rpn(L) when is_list(L) ->
[Res] = lists:foldl(fun rpn/2, [], string:tokens(L, " ")),
Res.
我們接下來將實作 rpn/2。請注意,由於表達式的每個運算符和運算元最終都會被放入堆疊頂部,因此已解決的表達式的結果將位於該堆疊上。我們需要在將其返回給使用者之前將最後一個值取出。這就是為什麼我們對 [Res] 進行模式比對並只返回 Res 的原因。
好吧,現在到比較難的部分。我們的 rpn/2 函數需要處理傳遞給它的所有值的堆疊。函數的標頭可能看起來像 rpn(Op,Stack),它的傳回值像 [NewVal|Stack]。當我們獲得常規數字時,操作將是
rpn(X, Stack) -> [read(X)|Stack].
在這裡,read/1 是一個將字串轉換為整數或浮點值的函數。遺憾的是,Erlang 中沒有內建函數來執行此操作(只有一個或另一個)。我們將自己添加它
read(N) ->
case string:to_float(N) of
{error,no_float} -> list_to_integer(N);
{F,_} -> F
end.
其中 string:to_float/1 將諸如 "13.37" 之類的字串轉換為其數值等效值。但是,如果無法讀取浮點值,它會返回 {error,no_float}。當這種情況發生時,我們需要改為呼叫 list_to_integer/1。
現在回到 rpn/2。我們遇到的數字都會被添加到堆疊中。但是,由於我們的模式與任何內容都匹配(請參閱模式比對),運算符也會被推到堆疊中。為了避免這種情況,我們將它們全部放入前面的子句中。我們將嘗試的第一個是加法
rpn("+", [N1,N2|S]) -> [N2+N1|S];
rpn(X, Stack) -> [read(X)|Stack].
我們可以看見,每當我們遇到 "+" 字串時,我們都會從堆疊頂部取出兩個數字 (N1,N2),將它們相加,然後將結果推回該堆疊。這與我們手工解決問題時應用的邏輯完全相同。嘗試該程式,我們可以看見它可以工作
1> c(calc).
{ok,calc}
2> calc:rpn("3 5 +").
8
3> calc:rpn("7 3 + 5 +").
15
剩下的事情很簡單,您只需要添加所有其他運算符即可
rpn("+", [N1,N2|S]) -> [N2+N1|S];
rpn("-", [N1,N2|S]) -> [N2-N1|S];
rpn("*", [N1,N2|S]) -> [N2*N1|S];
rpn("/", [N1,N2|S]) -> [N2/N1|S];
rpn("^", [N1,N2|S]) -> [math:pow(N2,N1)|S];
rpn("ln", [N|S]) -> [math:log(N)|S];
rpn("log10", [N|S]) -> [math:log10(N)|S];
rpn(X, Stack) -> [read(X)|Stack].
請注意,諸如對數之類的僅接受一個參數的函數只需要從堆疊中彈出一個元素。將諸如 'sum' 或 'prod' 之類的函數添加到練習中,這些函數會返回到目前為止讀取的所有元素的總和或它們的所有乘積。為了幫助您,它們已經在我的 calc.erl 版本中實作。
為了確保這一切正常,我們將編寫非常簡單的單元測試。Erlang 的 = 運算符可以充當斷言函數。斷言在遇到意外值時應崩潰,這正是我們所需要的。當然,Erlang 還有更進階的測試框架,包括 Common Test 和 EUnit。我們稍後會檢查它們,但現在基本的 = 就可以完成這項工作
rpn_test() ->
5 = rpn("2 3 +"),
87 = rpn("90 3 -"),
-4 = rpn("10 4 3 + 2 * -"),
-2.0 = rpn("10 4 3 + 2 * - 2 /"),
ok = try
rpn("90 34 12 33 55 66 + * - +")
catch
error:{badmatch,[_|_]} -> ok
end,
4037 = rpn("90 34 12 33 55 66 + * - + -"),
8.0 = rpn("2 3 ^"),
true = math:sqrt(2) == rpn("2 0.5 ^"),
true = math:log(2.7) == rpn("2.7 ln"),
true = math:log10(2.7) == rpn("2.7 log10"),
50 = rpn("10 10 10 20 sum"),
10.0 = rpn("10 10 10 20 sum 5 /"),
1000.0 = rpn("10 10 20 0.5 prod"),
ok.
測試函數嘗試所有操作;如果沒有引發例外狀況,則認為測試成功。前四個測試檢查基本算術函數是否正常運作。第五個測試指定了我尚未解釋的行為。try ... catch 預期會擲回一個 badmatch 錯誤,因為表達式無法運作
90 34 12 33 55 66 + * - + 90 (34 (12 (33 (55 66 +) *) -) +)
在 rpn/1 的末尾,值 -3947 和 90 留在堆疊中,因為沒有運算符可以對掛在那裡的 90 進行操作。有兩種方法可以處理這個問題:要么忽略它並僅取得堆疊頂部的值(這將是最後計算的結果),要么因為算術錯誤而崩潰。鑑於 Erlang 的策略是讓它崩潰,因此這裡選擇了這種方法。實際崩潰的部分是 rpn/1 中的 [Res]。這一個確保堆疊中只剩下一個元素,即結果。
之所以會有幾個 true = FunctionCall1 == FunctionCall2 形式的測試,是因為函式呼叫不能放在 = 的左側。它仍然像斷言一樣運作,因為我們會將比較的結果與 true 比較。
我也加入了 sum 和 prod 運算子的測試案例,你們可以自行練習實作。如果所有測試都成功,應該會看到以下結果
1> c(calc).
{ok,calc}
2> calc:rpn_test().
ok
3> calc:rpn("1 2 ^ 2 2 ^ 3 2 ^ 4 2 ^ sum 2 -").
28.0
其中 28 的確等於 sum(1² + 2² + 3² + 4²) - 2。你可以隨意嘗試更多次。
為了讓我們的計算機更好,可以考慮在因未知運算子或堆疊中留下數值而崩潰時,引發 badarith 錯誤,而不是目前的 badmatch 錯誤。這肯定能讓 calc 模組的使用者更容易除錯。
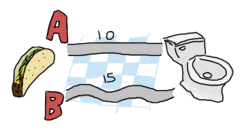
希斯洛到倫敦
我們的下一個問題也取自 Learn You a Haskell。你正搭乘飛機,預計在幾個小時內降落在希斯洛機場。你必須盡快趕到倫敦;你富有的叔叔快要過世了,你想成為第一個趕到那裡,以繼承他的遺產的人。
從希斯洛到倫敦有兩條主要道路,以及一些連接它們的小街道。由於速度限制和交通狀況,在某些道路和小街道上行駛的時間會比其他地方長。在飛機降落前,你決定找出到達他家的最佳路線,以最大化你的機會。這是你在筆記型電腦上找到的地圖
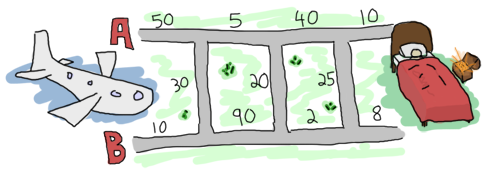
在閱讀了一些線上書籍後,你成了 Erlang 的忠實粉絲,因此決定使用該語言解決這個問題。為了方便使用地圖,你將資料以以下方式輸入名為 road.txt 的檔案中
50 10 30 5 90 20 40 2 25 10 8 0
道路的佈局模式為:A1, B1, X1, A2, B2, X2, ..., An, Bn, Xn,其中 X 是連接地圖 A 側和 B 側的道路之一。我們在最後一個 X 段插入 0,因為無論如何我們都已到達目的地。資料可以組織成 3 個元素的元組(三元組),形式為 {A,B,X}。
接下來你意識到,如果你一開始就不知道如何手動解決這個問題,那麼嘗試用 Erlang 解決這個問題是沒有意義的。為了做到這一點,我們將使用遞迴教給我們的東西。
撰寫遞迴函式時,首先要做的是找到我們的基本情況。對於目前的問題,如果我們只有一個元組要分析,也就是說,如果我們只需要在 A 和 B 之間做選擇(以及穿越 X,但在這種情況下沒有用,因為我們已經到達目的地)
那麼選擇就只剩下選擇 A 或 B 哪條路徑最短。如果你正確學習了遞迴,就會知道我們應該嘗試收斂到基本情況。這意味著在我們採取的每一步,我們都會希望將問題簡化為在下一步選擇 A 和 B。
讓我們擴展一下地圖,然後重新開始

啊!變得有趣了!我們如何將三元組 {5,1,3} 簡化為在 A 和 B 之間做出明確選擇?讓我們看看 A 有多少種可能的選項。要到達 A1 和 A2 的交點(我將其稱為點 A1),我可以直接走道路 A1(5),或從 B1(1)過來,然後穿越 X1(3)。在這種情況下,第一種選擇(5)比第二種選擇(4)長。對於選項 A,最短路徑是 [B, X]。那麼 B 的選項是什麼?你可以從 A1(5)開始,然後穿越 X1(3),或者直接走 B1 路徑(1)。
好吧!我們得到的是,前往第一個交點 A 的路徑 [B, X] 長度為 4,以及前往 B1 和 B2 交點的路徑 [B] 長度為 1。然後,我們必須決定要在前往第二個點 A(A2 與端點或 X2 的交點)和第二個點 B(B2 與 X2 的交點)之間選擇哪個。為了做出決定,我建議我們做和以前一樣的事情。現在你別無選擇,只能服從,因為我是寫這段文字的人。開始吧!
在這種情況下,所有可能的路徑都可以用與之前相同的方式找到。我們可以通過從 [B, X] 走 A2 路徑到達下一個點 A,這給我們 14 的長度(14 = 4 + 10),或者通過從 [B] 走 B2 然後 X2,這給我們 16 的長度(16 = 1 + 15 + 0)。在這種情況下,路徑 [B, X, A] 比 [B, B, X] 好。
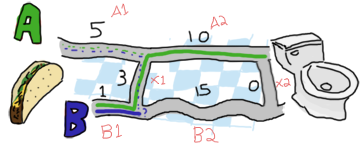
我們也可以通過從 [B, X] 走 A2 路徑,然後穿越 X2,長度為 14(14 = 4 + 10 + 0),或者通過從 [B] 走 B2 道路,長度為 16(16 = 1 + 15)到達下一個點 B。在這裡,最佳路徑是選擇第一個選項,[B, X, A, X]。
因此,當這個整個過程完成後,我們會剩下兩條路徑 A 或 B,兩者長度都為 14。它們中的任何一個都是正確的。最後的選擇總是會有兩條長度相同的路徑,因為最後一個 X 段的長度為 0。通過遞迴解決我們的問題,我們確保最終始終獲得最短路徑。還不錯吧?
很巧妙的是,我們已經為自己提供了建構遞迴函式所需的基本邏輯部分。如果你願意,可以實作它,但我承諾我們會自己寫很少的遞迴函式。我們將使用 fold。
注意:雖然我展示了如何使用和建構帶有列表的 fold,但 fold 代表一種更廣泛的概念,即使用累加器迭代資料結構。因此,可以針對樹、字典、陣列、資料庫表格等實作 fold。
在實驗時,使用像 map 和 fold 這樣的抽象有時很有用;它們可以讓你更容易地更改用於處理自己邏輯的資料結構。
我們到哪了?啊,對了!我們準備好了要作為輸入饋送的檔案。要進行檔案操作,file 模組是我們最好的工具。它包含許多常見於許多程式語言的函式,用於處理檔案本身(設定權限、移動檔案、重新命名和刪除檔案等)。
它還包含常用的檔案讀寫函式,例如: file:open/2 和 file:close/1(如其名稱所示,開啟和關閉檔案!)、file:read/2 取得檔案內容(以字串或二進位形式)、file:read_line/1 讀取單行、file:position/3 將開啟檔案的指標移動到給定的位置等等。
裡面也有許多捷徑函式,例如 file:read_file/1(開啟並以二進位形式讀取內容)、file:consult/1(開啟並將檔案解析為 Erlang 術語)或 file:pread/2(變更位置然後讀取)和 pwrite/2(變更位置並寫入內容)。
有了所有這些選項,找到一個讀取 road.txt 檔案的函式將很容易。因為我們知道我們的道路相對較小,我們將呼叫 file:read_file("road.txt").'
1> {ok, Binary} = file:read_file("road.txt").
{ok,<<"50\r\n10\r\n30\r\n5\r\n90\r\n20\r\n40\r\n2\r\n25\r\n10\r\n8\r\n0\r\n">>}
2> S = string:tokens(binary_to_list(Binary), "\r\n\t ").
["50","10","30","5","90","20","40","2","25","10","8","0"]
請注意,在這種情況下,我在有效的符號中加入了一個空格 (" ") 和一個 Tab ("\t"),因此檔案也可以寫成 "50 10 30 5 90 20 40 2 25 10 8 0" 的形式。給定此列表,我們需要將字串轉換為整數。我們將使用與 RPN 計算機中類似的方式
3> [list_to_integer(X) || X <- S]. [50,10,30,5,90,20,40,2,25,10,8,0]
讓我們啟動一個名為 road.erl 的新模組,並將此邏輯寫下來
-module(road).
-compile(export_all).
main() ->
File = "road.txt",
{ok, Bin} = file:read_file(File),
parse_map(Bin).
parse_map(Bin) when is_binary(Bin) ->
parse_map(binary_to_list(Bin));
parse_map(Str) when is_list(Str) ->
[list_to_integer(X) || X <- string:tokens(Str,"\r\n\t ")].
函式 main/0 負責讀取檔案的內容並將其傳遞給 parse_map/1。因為我們使用函式 file:read_file/1 從 road.txt 中取得內容,所以我們取得的結果是二進位制。因此,我讓函式 parse_map/1 比對列表和二進位制。如果是二進位制,我們只需將字串轉換為列表,然後再次呼叫該函式(我們的分割字串函式僅適用於列表)。
解析地圖的下一步是將資料重新分組為先前所述的 {A,B,X} 形式。遺憾的是,沒有簡單通用的方法可以一次從列表中提取 3 個元素,因此我們必須在遞迴函式中使用模式比對來執行此操作
group_vals([], Acc) ->
lists:reverse(Acc);
group_vals([A,B,X|Rest], Acc) ->
group_vals(Rest, [{A,B,X} | Acc]).
該函式以標準的尾遞迴方式運作;這裡沒有太複雜的事情發生。我們只需要稍微修改 parse_map/1 來呼叫它
parse_map(Bin) when is_binary(Bin) ->
parse_map(binary_to_list(Bin));
parse_map(Str) when is_list(Str) ->
Values = [list_to_integer(X) || X <- string:tokens(Str,"\r\n\t ")],
group_vals(Values, []).
如果我們嘗試編譯所有內容,現在應該會有一個有意義的道路
1> c(road).
{ok,road}
2> road:main().
[{50,10,30},{5,90,20},{40,2,25},{10,8,0}]
啊,是的,看起來沒錯。我們取得了撰寫函式所需的區塊,然後將其放入 fold 中。為了使其運作,必須找到一個好的累加器。
為了決定使用什麼作為累加器,我發現最容易使用的方法是想像自己處於演算法的中間執行過程中。對於這個特定的問題,我會想像自己目前正在嘗試找到第二個三元組 ({5,90,20}) 的最短路徑。為了決定哪條路徑是最佳的,我需要從前一個三元組取得結果。幸運的是,我們知道如何做到這一點,因為我們不需要累加器,而且我們已經取得所有邏輯。所以對於 A
 yet!")
並取這兩條路徑中最短的一條。對於 B,情況類似

所以現在我們知道,從 A 出發的目前最佳路徑是 [B, X]。我們也知道它的長度是 40。對於 B,路徑僅僅是 [B],長度是 10。我們可以使用此資訊,通過重新應用相同的邏輯,但計算運算式中的先前路徑,來找到下一個 A 和 B 的最佳路徑。我們需要的另一個資料是行走路徑,以便我們可以向使用者顯示它。由於我們需要兩條路徑(A 一條,B 一條)和兩個累積長度,因此我們的累加器可以採用 {{DistanceA, PathA}, {DistanceB, PathB}} 的形式。這樣,fold 的每次迭代都可以存取所有狀態,而且我們會建構它,以便最後向使用者顯示。
這給了我們函式需要的所有參數:{A,B,X} 三元組和 {{DistanceA,PathA}, {DistanceB,PathB}} 形式的累加器。
為了取得我們的累加器,可以通過以下方式將其放入程式碼中
shortest_step({A,B,X}, {{DistA,PathA}, {DistB,PathB}}) ->
OptA1 = {DistA + A, [{a,A}|PathA]},
OptA2 = {DistB + B + X, [{x,X}, {b,B}|PathB]},
OptB1 = {DistB + B, [{b,B}|PathB]},
OptB2 = {DistA + A + X, [{x,X}, {a,A}|PathA]},
{erlang:min(OptA1, OptA2), erlang:min(OptB1, OptB2)}.
在這裡,OptA1 取得 A 的第一個選項(通過 A),OptA2 取得第二個選項(通過 B 然後 X)。變數 OptB1 和 OptB2 對於點 B 取得類似的處理。最後,我們將取得的路徑與累加器一起傳回。
關於上面程式碼中儲存的路徑,請注意,我決定使用 [{x,X}] 的形式,而不是 [x],原因很簡單,使用者可能會想知道每個線段的長度。我做的另一件事是以反向方式累積路徑({x,X} 出現在 {b,B} 之前)。這是因為我們在一個 fold 迴圈中,它是尾遞迴的:整個列表會反轉,所以有必要把最後遍歷的路徑放在其他路徑之前。
最後,我使用 erlang:min/2 來找到最短路徑。在元組上使用這種比較函數可能聽起來很奇怪,但請記住,每個 Erlang term 都可以與其他任何 term 進行比較!因為長度是元組的第一個元素,所以我們可以依此對它們進行排序。
接下來要做的是把這個函數放入一個 fold 迴圈中。
optimal_path(Map) ->
{A,B} = lists:foldl(fun shortest_step/2, {{0,[]}, {0,[]}}, Map),
{_Dist,Path} = if hd(element(2,A)) =/= {x,0} -> A;
hd(element(2,B)) =/= {x,0} -> B
end,
lists:reverse(Path).
在 fold 迴圈結束時,兩條路徑的距離應該相同,除非其中一條路徑經過最後的 {x,0} 線段。if 會查看兩條路徑最後訪問的元素,並返回不經過 {x,0} 的那條路徑。選擇步數最少的路徑(與 length/1 比較)也可以。選擇最短路徑後,將其反轉(它是以尾遞迴的方式建立的;你必須反轉它)。然後你可以將它顯示給世界,或者保密它並獲得你富有的叔叔的遺產。要做到這一點,你必須修改主函數以呼叫 optimal_path/1。然後就可以編譯它了。
main() ->
File = "road.txt",
{ok, Bin} = file:read_file(File),
optimal_path(parse_map(Bin)).
喔,你看!我們得到了正確的答案!做得好!
1> c(road).
{ok,road}
2> road:main().
[{b,10},{x,30},{a,5},{x,20},{b,2},{b,8}]
或者,用視覺化的方式表達
![The shortest path, going through [b,x,a,x,b,b]](https://learnyousomeerlang.dev.org.tw/static/img/road1.4.png)
但是你知道什麼會真的很有用嗎?那就是能夠從 Erlang shell 之外執行我們的程式。我們需要再次更改主函數
main([FileName]) ->
{ok, Bin} = file:read_file(FileName),
Map = parse_map(Bin),
io:format("~p~n",[optimal_path(Map)]),
erlang:halt().
主函數現在的 arity 為 1,這是從命令列接收參數所必需的。我也新增了函數 erlang:halt/0,它會在被呼叫後關閉 Erlang VM。我也將對 optimal_path/1 的呼叫包裝在 io:format/2 中,因為這是讓文字在 Erlang shell 之外可見的唯一方法。
有了這一切,你的 road.erl 檔案現在應該看起來像這樣(減去註解)
-module(road).
-compile(export_all).
main([FileName]) ->
{ok, Bin} = file:read_file(FileName),
Map = parse_map(Bin),
io:format("~p~n",[optimal_path(Map)]),
erlang:halt(0).
%% Transform a string into a readable map of triples
parse_map(Bin) when is_binary(Bin) ->
parse_map(binary_to_list(Bin));
parse_map(Str) when is_list(Str) ->
Values = [list_to_integer(X) || X <- string:tokens(Str,"\r\n\t ")],
group_vals(Values, []).
group_vals([], Acc) ->
lists:reverse(Acc);
group_vals([A,B,X|Rest], Acc) ->
group_vals(Rest, [{A,B,X} | Acc]).
%% Picks the best of all paths, woo!
optimal_path(Map) ->
{A,B} = lists:foldl(fun shortest_step/2, {{0,[]}, {0,[]}}, Map),
{_Dist,Path} = if hd(element(2,A)) =/= {x,0} -> A;
hd(element(2,B)) =/= {x,0} -> B
end,
lists:reverse(Path).
%% actual problem solving
%% change triples of the form {A,B,X}
%% where A,B,X are distances and a,b,x are possible paths
%% to the form {DistanceSum, PathList}.
shortest_step({A,B,X}, {{DistA,PathA}, {DistB,PathB}}) ->
OptA1 = {DistA + A, [{a,A}|PathA]},
OptA2 = {DistB + B + X, [{x,X}, {b,B}|PathB]},
OptB1 = {DistB + B, [{b,B}|PathB]},
OptB2 = {DistA + A + X, [{x,X}, {a,A}|PathA]},
{erlang:min(OptA1, OptA2), erlang:min(OptB1, OptB2)}.
然後執行程式碼
$ erlc road.erl
$ erl -noshell -run road main road.txt
[{b,10},{x,30},{a,5},{x,20},{b,2},{b,8}]
沒錯,它是正確的!這幾乎是你讓事情運作所需做的一切。你可以製作一個 bash/batch 檔案將該行包裝成一個可執行檔,或者你可以查看 escript 以獲得類似的結果。
正如我們在這兩個練習中所看到的,當你將問題分解成可以單獨解決的小部分,然後再將所有部分組合在一起時,解決問題會容易得多。不了解就直接編寫程式也沒什麼價值。最後,進行一些測試總是值得讚賞的。它們會讓你確保一切運作良好,並讓你可以在不改變最終結果的情況下更改程式碼。