更多關於多進程
宣告您的狀態

前一章節中展示的範例對於演示目的來說都還不錯,但您只用這些工具是走不遠的。並不是說這些範例不好,主要是因為如果進程和 actors 僅是具有訊息的函式,那它們就沒有太大的優勢。為了修正這個問題,我們必須能夠在進程中保持狀態。
首先,我們在新的 kitchen.erl 模組中建立一個函式,讓進程表現得像冰箱。該進程將允許兩個操作:將食物儲存在冰箱中和從冰箱中取出食物。應該只能取出之前已儲存的食物。以下函式可以作為我們進程的基礎
-module(kitchen).
-compile(export_all).
fridge1() ->
receive
{From, {store, _Food}} ->
From ! {self(), ok},
fridge1();
{From, {take, _Food}} ->
%% uh....
From ! {self(), not_found},
fridge1();
terminate ->
ok
end.
它有些問題。當我們要求儲存食物時,進程應該回覆 ok,但實際上沒有任何東西儲存食物;fridge1() 被呼叫,然後函式從頭開始,沒有狀態。您也可以看到,當我們呼叫進程從冰箱取出食物時,沒有狀態可以取出,因此唯一能回覆的就是 not_found。為了儲存和取出食物項目,我們需要在函式中加入狀態。
在遞迴的幫助下,進程的狀態可以完全保持在函式的參數中。以我們的冰箱進程為例,一種可能性是將所有食物儲存為一個列表,然後在有人需要吃東西時在這個列表中尋找
fridge2(FoodList) ->
receive
{From, {store, Food}} ->
From ! {self(), ok},
fridge2([Food|FoodList]);
{From, {take, Food}} ->
case lists:member(Food, FoodList) of
true ->
From ! {self(), {ok, Food}},
fridge2(lists:delete(Food, FoodList));
false ->
From ! {self(), not_found},
fridge2(FoodList)
end;
terminate ->
ok
end.
首先要注意的是 fridge2/1 接受一個參數,FoodList。您可以看到,當我們發送符合 {From, {store, Food}} 的訊息時,函式會在離開之前將 Food 加入 FoodList。一旦完成遞迴呼叫,就可以檢索相同的項目。事實上,我已經在那裡實作了它。該函式使用 lists:member/2 來檢查 Food 是否為 FoodList 的一部分。根據結果,該項目會被送回呼叫進程(並從 FoodList 中刪除),否則會送回 not_found
1> c(kitchen).
{ok,kitchen}
2> Pid = spawn(kitchen, fridge2, [[baking_soda]]).
<0.51.0>
3> Pid ! {self(), {store, milk}}.
{<0.33.0>,{store,milk}}
4> flush().
Shell got {<0.51.0>,ok}
ok
將物品儲存在冰箱中似乎有效。我們會嘗試更多東西,然後嘗試從冰箱中取出。
5> Pid ! {self(), {store, bacon}}.
{<0.33.0>,{store,bacon}}
6> Pid ! {self(), {take, bacon}}.
{<0.33.0>,{take,bacon}}
7> Pid ! {self(), {take, turkey}}.
{<0.33.0>,{take,turkey}}
8> flush().
Shell got {<0.51.0>,ok}
Shell got {<0.51.0>,{ok,bacon}}
Shell got {<0.51.0>,not_found}
ok
如預期,我們可以從冰箱中取出培根,因為我們已經先將它放入(連同牛奶和蘇打粉),但冰箱進程在我們要求時沒有火雞可以找到。這就是為什麼我們會收到最後的 {<0.51.0>,not_found} 訊息。
我們喜歡訊息,但我們對它們保密
之前範例中令人惱火的一件事是,將要使用冰箱的程式設計師必須知道為該進程發明的協定。這是一個無用的負擔。解決此問題的一個好方法是藉助處理接收和發送訊息的函式來抽象化訊息
store(Pid, Food) ->
Pid ! {self(), {store, Food}},
receive
{Pid, Msg} -> Msg
end.
take(Pid, Food) ->
Pid ! {self(), {take, Food}},
receive
{Pid, Msg} -> Msg
end.
現在與進程的互動更加清晰
9> c(kitchen).
{ok,kitchen}
10> f().
ok
11> Pid = spawn(kitchen, fridge2, [[baking_soda]]).
<0.73.0>
12> kitchen:store(Pid, water).
ok
13> kitchen:take(Pid, water).
{ok,water}
14> kitchen:take(Pid, juice).
not_found
我們不必再擔心訊息是如何運作的,是否需要發送 self() 或像 take 或 store 這樣的精確原子:所需要的只是一個 pid 以及知道要呼叫哪些函式。這隱藏了所有髒活,並使建立冰箱進程更容易。
剩下的一件事就是隱藏關於需要產生進程的整個部分。我們處理了隱藏訊息,但我們仍然希望使用者處理進程的建立。我將加入以下 start/1 函式
start(FoodList) ->
spawn(?MODULE, fridge2, [FoodList]).
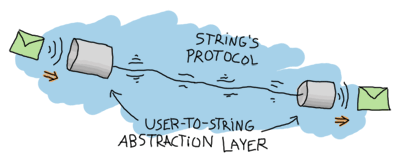
這裡,?MODULE 是一個巨集,會回傳目前模組的名稱。撰寫這樣一個函式似乎沒有任何優勢,但實際上有一些。它的本質部分將與呼叫 take/2 和 store/2 一致:關於冰箱進程的所有事情現在都由 kitchen 模組處理。如果您要在冰箱進程啟動時加入記錄,或啟動第二個進程(例如冷凍庫),在我們的 start/1 函式中會非常容易做到。但是,如果產生活動留給使用者透過 spawn/3 來完成,那麼每個啟動冰箱的地方現在都需要加入新的呼叫。這容易出錯,而錯誤很糟糕。
讓我們看看如何使用這個函式
15> f().
ok
16> c(kitchen).
{ok,kitchen}
17> Pid = kitchen:start([rhubarb, dog, hotdog]).
<0.84.0>
18> kitchen:take(Pid, dog).
{ok,dog}
19> kitchen:take(Pid, dog).
not_found
耶!狗已經從冰箱裡出來了,我們的抽象化已經完成!
逾時
讓我們在 pid(A,B,C) 命令的幫助下嘗試一些小事情,這可以讓我們將 3 個整數 A、B 和 C 變為一個 pid。在這裡,我們將故意餵給 kitchen:take/2 一個假的 pid
20> kitchen:take(pid(0,250,0), dog).
哎呀。shell 凍結了。發生這種情況的原因是 take/2 的實作方式。為了了解發生了什麼,讓我們首先複習一下正常情況下發生的事情
- 從您(shell)向冰箱進程發送一則訊息,以取出食物;
- 您的進程切換到接收模式,並等待新的訊息;
- 冰箱移除物品並將其發送到您的進程;
- 您的進程收到它,並繼續它的生活。

以下是 shell 凍結時發生的事情
- 從您(shell)向未知進程發送一則訊息,以取出食物;
- 您的進程切換到接收模式,並等待新的訊息;
- 未知的進程不是不存在,就是不期望收到這樣的訊息,並且對其不做任何處理;
- 您的 shell 進程卡在接收模式中。
這很令人惱火,尤其因為這裡不可能進行錯誤處理。沒有發生任何非法的事情,程式只是在等待。一般來說,任何處理非同步操作的事情(這就是在 Erlang 中完成訊息傳遞的方式)如果沒有收到任何資料的跡象,都需要一種在一定時間後放棄的方法。當頁面或影像載入時間過長時,網路瀏覽器會執行此操作;當某人在接電話或在會議中遲到時,您也會這樣做。Erlang 當然有適合的機制來實現這一點,而且它是 receive 結構的一部分
receive
Match -> Expression1
after Delay ->
Expression2
end.
receive 和 after 之間的部分與我們已經知道的完全相同。如果已經過了 Delay(代表毫秒的整數)的時間,但沒有收到符合 Match 模式的訊息,則會觸發 after 部分。當發生這種情況時,會執行 Expression2。
我們會撰寫兩個新的介面函式,store2/2 和 take2/2,它們的行為會與 store/2 和 take/2 完全相同,例外之處是它們會在 3 秒後停止等待
store2(Pid, Food) ->
Pid ! {self(), {store, Food}},
receive
{Pid, Msg} -> Msg
after 3000 ->
timeout
end.
take2(Pid, Food) ->
Pid ! {self(), {take, Food}},
receive
{Pid, Msg} -> Msg
after 3000 ->
timeout
end.
現在您可以透過 ^G 解凍 shell,並嘗試新的介面函式
User switch command
--> k
--> s
--> c
Eshell V5.7.5 (abort with ^G)
1> c(kitchen).
{ok,kitchen}
2> kitchen:take2(pid(0,250,0), dog).
timeout
現在它運作了。
注意:我說過 after 只接受毫秒作為值,但實際上可以使用原子 infinity。雖然這在許多情況下沒有用(您可能只是完全刪除 after 子句),但有時會在程式設計師可以將等待時間提交給預期接收結果的函式時使用。這樣一來,如果程式設計師真的想永遠等待,他就可以這樣做。
除了在時間過長後放棄之外,這種計時器還有其他用途。一個非常簡單的例子是我們之前使用的 timer:sleep/1 函式是如何運作的。以下是它的實作方式(讓我們將其放入新的 multiproc.erl 模組中)
sleep(T) ->
receive
after T -> ok
end.
在這種特定情況下,該結構的 receive 部分中永遠不會匹配任何訊息,因為沒有模式。相反,一旦經過延遲 T,就會呼叫該結構的 after 部分。
另一種特殊情況是逾時時間為 0
flush() ->
receive
_ -> flush()
after 0 ->
ok
end.
當發生這種情況時,Erlang VM 會嘗試尋找符合可用模式之一的訊息。在上面的情況中,任何內容都符合。只要有訊息,flush/0 函式就會遞迴呼叫自身,直到信箱為空。完成此操作後,會執行程式碼的 after 0 -> ok 部分,並且函式會回傳。
選擇性接收
這個「刷新」概念使得實作選擇性接收成為可能,它可以透過巢狀呼叫來優先處理您接收的訊息
important() ->
receive
{Priority, Message} when Priority > 10 ->
[Message | important()]
after 0 ->
normal()
end.
normal() ->
receive
{_, Message} ->
[Message | normal()]
after 0 ->
[]
end.
此函式將建立所有訊息的列表,其中優先順序高於 10 的訊息會先出現
1> c(multiproc).
{ok,multiproc}
2> self() ! {15, high}, self() ! {7, low}, self() ! {1, low}, self() ! {17, high}.
{17,high}
3> multiproc:important().
[high,high,low,low]
因為我使用了 after 0 位元,所以會取得每個訊息,直到沒有剩餘訊息,但進程會先嘗試抓取所有優先順序高於 10 的訊息,然後才會考慮在 normal/0 呼叫中累積的其他訊息。
如果這種實作看起來很有趣,請注意,由於 Erlang 中選擇性接收的運作方式,有時會不安全。
當訊息被傳送到一個進程時,它們會被儲存在信箱中,直到該進程讀取它們並且它們在那裡符合模式。如上一章所述,這些訊息會按照它們收到的順序儲存。這表示每次您匹配訊息時,它都會從最舊的訊息開始。
然後會針對 receive 的每個模式嘗試該最舊的訊息,直到其中一個符合。當它符合時,訊息會從信箱中移除,並且進程的程式碼會正常執行,直到下一個 receive。當評估下一個 receive 時,VM 將會尋找目前在信箱中最舊的訊息(我們移除的訊息之後的訊息),依此類推。

當沒有辦法匹配給定的訊息時,會將其放入儲存佇列,並嘗試下一個訊息。如果第二個訊息符合,則會將第一個訊息放回信箱頂部,以便稍後重試。

這讓您只需關心有用的訊息。忽略某些訊息以便稍後以上述方式處理,是選擇性接收的精髓。雖然它們很有用,但問題在於如果您的處理程序有很多您從不關心的訊息,讀取有用的訊息實際上會花費越來越長的時間(而且處理程序的大小也會增加)。
在上面的圖中,想像我們想要第 367 條訊息,但前 366 條是我們程式碼忽略的垃圾訊息。為了取得第 367 條訊息,處理程序需要嘗試比對前 366 條訊息。一旦完成且它們都已放入佇列,則取出第 367 條訊息,並將前 366 條訊息放回郵箱的頂部。下一個有用的訊息可能會被埋得更深,需要更長的時間才能找到。
這種接收方式是 Erlang 中效能問題的常見原因。如果您的應用程式執行緩慢,並且您知道有很多訊息在傳遞,這可能是原因所在。
如果這種選擇性接收有效地導致您的程式碼大幅減速,首先要問自己的是,為什麼會收到您不想要的訊息?訊息是否發送到正確的處理程序?模式是否正確?訊息格式是否錯誤?您是否在應該有多個處理程序的地方只使用一個?回答其中一個或多個問題可以解決您的問題。
由於無用的訊息污染處理程序的郵箱的風險,Erlang 程式設計師有時會採取防禦措施來應對此類事件。一種標準的方法可能如下所示:
receive
Pattern1 -> Expression1;
Pattern2 -> Expression2;
Pattern3 -> Expression3;
...
PatternN -> ExpressionN;
Unexpected ->
io:format("unexpected message ~p~n", [Unexpected])
end.
這樣做的目的是確保任何訊息至少會符合一個子句。Unexpected 變數將符合任何訊息,將非預期的訊息從郵箱中取出並顯示警告。根據您的應用程式,您可能希望將訊息儲存到某種記錄設施中,以便稍後能夠找到有關它的資訊:如果訊息發送到錯誤的處理程序,那將會很可惜,因為這樣會永遠失去它們,並且很難找出為什麼另一個處理程序沒有收到它應該收到的東西。
如果您確實需要在訊息中處理優先順序,並且無法使用這樣的萬用子句,更明智的方法是實作最小堆積或使用 gb_trees 模組,並將每個收到的訊息都放入其中(請務必將優先順序數字放在鍵的第一個位置,以便將其用於排序訊息)。然後,您可以根據您的需求,搜尋資料結構中最小或最大的元素。
在大多數情況下,與選擇性接收相比,此技術應該可以讓您更有效率地接收具有優先順序的訊息。但是,如果您收到的大多數訊息都具有最高優先順序,它可能會減慢您的速度。像往常一樣,訣竅是在最佳化之前進行分析和測量。
注意: 自 R14A 起,Erlang 的編譯器新增了一種新的最佳化。它簡化了處理程序之間來回通訊的特定情況下的選擇性接收。此類函數的一個範例是multiproc.erl中的 optimized/1。
為了使其運作,必須在函數中建立一個參考(make_ref()),然後在訊息中傳送。在同一個函數中,然後進行選擇性接收。如果除非包含相同的參考,否則沒有訊息可以匹配,則編譯器會自動確保 VM 會跳過在建立該參考之前收到的訊息。
請注意,您不應嘗試強迫您的程式碼符合此類最佳化。Erlang 開發人員只會尋找常用的模式,然後使其速度更快。如果您編寫慣用的程式碼,最佳化應該會隨之而來。而不是反過來。
理解這些概念之後,下一步將是使用多個處理程序進行錯誤處理。