開始(認真的)
Erlang 是一種相對小而簡單的語言(就像 C 比 C++ 簡單的方式)。該語言內建了一些基本的資料型別,因此,本章將涵蓋大多數這些型別。強烈建議您閱讀它,因為它解釋了您之後將使用 Erlang 編寫的所有程式的基礎。
數字
在 Erlang Shell 中,表達式必須以句點後接空白字元(換行符號、空格等)結尾,否則它們將不會被執行。您可以用逗號分隔表達式,但只會顯示最後一個表達式的結果(其他表達式仍然會被執行)。對於大多數人來說,這肯定是不同尋常的語法,它來自 Erlang 直接在 Prolog(一種邏輯程式語言)中實作的時代。
開啟先前章節中描述的 Erlang Shell,讓我們輸入一些東西!
1> 2 + 15. 17 2> 49 * 100. 4900 3> 1892 - 1472. 420 4> 5 / 2. 2.5 5> 5 div 2. 2 6> 5 rem 2. 1
您應該已經注意到 Erlang 不在意您輸入的是浮點數還是整數:在處理算術時,兩種型別都受到支援。 整數和浮點數幾乎是 Erlang 數學運算子會為您透明處理的唯一資料型別。但是,如果您想要整數除法,請使用
整數和浮點數幾乎是 Erlang 數學運算子會為您透明處理的唯一資料型別。但是,如果您想要整數除法,請使用 div,而要使用模數運算子,請使用 rem(餘數)。
請注意,我們可以在單個表達式中使用多個運算子,而數學運算會遵守正常的優先順序規則。
7> (50 * 100) - 4999. 1 8> -(50 * 100 - 4999). -1 9> -50 * (100 - 4999). 244950
如果您想以十進制以外的其他進制來表示整數,只需輸入數字為 Base#Value(給定 Base 的範圍為 2..36)
10> 2#101010. 42 11> 8#0677. 447 12> 16#AE. 174
太棒了!Erlang 具有您桌角計算機的功能,而且上面還有一個奇怪的語法!絕對令人興奮!
不可變的變數
進行算術運算還可以,但是如果您無法將結果儲存在某個地方,就無法走遠。為此,我們將使用變數。如果您已閱讀本書的簡介,您將知道變數在函數式程式設計中不能是變數。可以使用以下 7 個表達式來示範變數的基本行為(請注意,變數以大寫字母開頭)
1> One. * 1: variable 'One' is unbound 2> One = 1. 1 3> Un = Uno = One = 1. 1 4> Two = One + One. 2 5> Two = 2. 2 6> Two = Two + 1. ** exception error: no match of right hand side value 3 7> two = 2. ** exception error: no match of right hand side value 2
這些指令告訴我們的第一件事是,您只能將一個值指定給一個變數一次;然後,如果它已經具有相同的值,您可以「假裝」將一個值指定給一個變數。如果值不同,Erlang 會抱怨。這是一個正確的觀察,但是解釋有點複雜,並且取決於 = 運算子。= 運算子(而不是變數)的作用是比較值,如果它們不同,則會抱怨。如果它們相同,則會傳回該值
8> 47 = 45 + 2. 47 9> 47 = 45 + 3. ** exception error: no match of right hand side value 48
當此運算子與變數混合使用時,如果左側的項是變數,且該變數是未繫結的(沒有與之關聯的值),則 Erlang 會自動將右側的值繫結到左側的變數。比較將因此成功,並且變數將把該值保留在記憶體中。
= 運算子的這種行為是稱為「模式比對」的基礎,許多函數式程式語言都具有這種行為,儘管 Erlang 的方式通常被認為比其他替代方案更靈活和完整。當我們在本章中訪問元組和列表型別時,以及在以下章節中訪問函數時,我們將更詳細地了解模式比對。
指令 1-7 告訴我們的另一件事是,變數名稱必須以大寫字母開頭。指令 7 失敗,因為單字 two 以小寫字母開頭。從技術上講,變數也可以以下底線 ('_') 開頭,但依照慣例,它們的使用僅限於您不在乎的值,但您覺得有必要記錄其中包含的內容。
您也可以使用僅為底線的變數
10> _ = 14+3. 17 11> _. * 1: variable '_' is unbound
與任何其他類型的變數不同,它永遠不會儲存任何值。現在完全沒用,但是當我們需要它時您就會知道它的存在。
注意:如果您在 Shell 中測試並將錯誤的值儲存到變數,可以使用函式 f(Variable). 來「刪除」該變數。如果您希望清除所有變數名稱,請執行 f().。
這些函式僅在您測試時提供協助,並且僅在 Shell 中有效。在編寫實際程式時,我們將無法以這種方式銷毀值。如果您承認 Erlang 可在工業場景中使用,那麼只能在 Shell 中執行此操作是有道理的:完全有可能使 Shell 在沒有中斷的情況下保持活動狀態數年...讓我們打賭,變數 X 在這段時間內將被使用多次。
原子
變數名稱不能以小寫字元開頭的原因是:原子。原子是字面值,是具有自身名稱作為值的常數。您看到的就是您得到的,不要期望更多。原子 cat 的意思是「cat」,僅此而已。您不能玩弄它,不能更改它,不能將它粉碎;它是 cat。接受它。
雖然以小寫字母開頭的單字是一種撰寫原子符號的方式,但撰寫方式不只一種
1> atom. atom 2> atoms_rule. atoms_rule 3> atoms_rule@erlang. atoms_rule@erlang 4> 'Atoms can be cheated!'. 'Atoms can be cheated!' 5> atom = 'atom'. atom
如果原子符號不是以小寫字母開頭,或者如果它包含字母數字字元、底線 (_),或 @ 以外的其他字元,則應以單引號 (') 括起來。
表達式 5 也顯示,帶有單引號的原子與沒有單引號的類似原子完全相同。
我將原子與具有其名稱作為其值的常數進行比較。您可能已經使用過使用常數的程式碼:例如,假設我具有眼睛顏色的值:
BLUE -> 1, BROWN -> 2, GREEN -> 3, OTHER -> 4。您需要將常數的名稱與某些基礎值進行匹配。原子可讓您忘記基礎值:我的眼睛顏色可以簡單地是 'blue'、'brown'、'green' 和 'other'。這些顏色可以在任何程式碼的任何地方使用:基礎值永遠不會衝突,並且此類常數不可能未定義!如果您真的想要具有與之關聯值的常數,則有一種方法可以做到這一點,我們將在第 4 章(模組)中看到它。
因此,原子符號主要用於表達或限定與之關聯的資料。單獨使用時,很難找到它的好處。這就是為什麼我們不會花更多時間去玩弄它們的原因;它們的最佳用途將在與其他類型的資料結合使用時出現。
不要喝太多 Kool-Aid
原子符號真的很好,是傳送訊息或表示常數的好方法。但是,將原子符號用於太多事物存在陷阱:原子符號在「原子符號表」中被引用,這會消耗記憶體(在 32 位元系統中為每個原子符號 4 個位元組,在 64 位元系統中為每個原子符號 8 個位元組)。原子符號表不會被垃圾回收,因此原子符號會不斷累積,直到系統因記憶體使用量或因為宣告了 1048577 個原子符號而崩潰。
這表示不應以任何理由動態產生原子符號;如果您的系統必須可靠,並且使用者輸入讓某人透過告知它建立原子符號來隨意使其崩潰,那麼您就會遇到麻煩。原子符號應被視為開發人員的工具,因為老實說,它們就是這樣。
注意:某些原子符號是保留字,除了語言設計人員希望它們成為的用途之外,不能使用:函式名稱、運算子、表達式等。這些是: after and andalso band begin bnot bor bsl bsr bxor case catch cond div end fun if let not of or orelse query receive rem try when xor

布林代數 & 比較運算子
如果一個人無法分辨大小、真假之間的差異,那麼他就會陷入非常深的麻煩。與任何其他語言一樣,Erlang 具有讓您可以使用布林運算並比較項目的方法。
布林代數非常簡單
1> true and false. false 2> false or true. true 3> true xor false. true 4> not false. true 5> not (true and true). false
注意:布林運算子 and 和 or 將始終評估運算子兩側的引數。如果您想要短路運算子(僅在需要時才評估右側引數),請使用 andalso 和 orelse。
測試是否相等或不相等也很簡單,但其符號與您在許多其他語言中看到的符號略有不同
6> 5 =:= 5. true 7> 1 =:= 0. false 8> 1 =/= 0. true 9> 5 =:= 5.0. false 10> 5 == 5.0. true 11> 5 /= 5.0. false
首先,如果您的常用語言使用 == 和 != 來測試相等性和不等性,則 Erlang 使用 =:= 和 =/=。最後三個表達式(第 9 至 11 行)也向我們介紹了一個陷阱:Erlang 不會在乎算術中的浮點數和整數,但在比較它們時會這樣做。不過不用擔心,因為 == 和 /= 運算子可在此情況下為您提供協助。無論您是否想要精確的相等性,記住這一點都很重要。
其他用於比較的運算子是 <(小於)、>(大於)、>=(大於或等於)和 =<(小於或等於)。最後一個運算子是反向的(在我看來),並且是我程式碼中許多語法錯誤的來源。請留意 =<。
12> 1 < 2. true 13> 1 < 1. false 14> 1 >= 1. true 15> 1 =< 1. true
當執行 5 + llama 或 5 == true 時會發生什麼?沒有比嘗試它並隨後被錯誤訊息嚇到更好的方法了!
12> 5 + llama.
** exception error: bad argument in an arithmetic expression
in operator +/2
called as 5 + llama
哎呀!Erlang 並不真的喜歡您誤用其某些基本型別!模擬器在此處傳回了一個不錯的錯誤訊息。它告訴我們,它不喜歡在 + 運算子周圍使用的兩個引數之一!
Erlang 對於錯誤的型別感到惱火並不總是如此
13> 5 =:= true. false
為什麼它在某些運算中拒絕不同的型別,但在其他運算中不拒絕?雖然 Erlang 不允許您將任何東西與所有東西相加,但它會讓您比較它們。這是因為 Erlang 的創建者認為實用主義勝過理論,並決定能夠簡單地編寫諸如可以對任何項目排序的通用排序演算法會很棒。它的目的是簡化您的生活,並且可以在大多數時間這樣做。
在進行布林代數和比較時,還需要記住最後一件事
14> 0 == false. false 15> 1 < false. true
如果您來自程序式語言或大多數物件導向語言,您很可能會抓狂。第 14 行應評估為 true,第 15 行應評估為 false!畢竟,false 表示 0,而 true 表示其他任何值!除了在 Erlang 中。因為我對您撒謊了。是的,我這樣做了。我真可恥。
Erlang 沒有布林值 true 和 false。術語 true 和 false 是原子符號,但它們與語言整合得很好,只要您不期望 false 和 true 表示 false 和 true 以外的任何東西,您就不會有問題。
注意:比較中每個元素的正確順序如下
數字 < 原子符號 < 參照 < 函式 < 連接埠 < PID < 元組 < 列表 < 位元字串
您還不知道所有這些型別的事物,但您將透過本書了解它們。請記住,這就是為什麼您可以使用任何東西與任何東西進行比較!引用 Erlang 的創建者之一 Joe Armstrong 的話:「實際的順序並不重要 - 但總順序定義良好是很重要的。」
元組
元組是一種組織資料的方式。當您知道有多少個術語時,它是一種將許多術語組合在一起的方式。在 Erlang 中,元組以 {Element1, Element2, ..., ElementN} 的形式撰寫。例如,如果您想告訴我笛卡爾圖中的點的位置,您會給我坐標 (x,y)。我們可以將此點表示為兩個項目的元組
1> X = 10, Y = 4.
4
2> Point = {X,Y}.
{10,4}
在這種情況下,一個點永遠會是兩個項。你只需要處理一個變數,而不是到處帶著變數 X 和 Y。但是,如果我收到一個點,而且我只想要 X 坐標,該怎麼辦呢?提取該資訊並不難。請記住,當我們賦值時,如果它們相同,Erlang 永遠不會抱怨。讓我們利用這一點!你可能需要用 f() 清理我們設定的變數。
3> Point = {4,5}.
{4,5}
4> {X,Y} = Point.
{4,5}
5> X.
4
6> {X,_} = Point.
{4,5}
從那時起,我們就可以用 X 來取得元組的第一個值了!這是怎麼發生的? 首先,X 和 Y 沒有值,因此被視為未綁定的變數。當我們在
首先,X 和 Y 沒有值,因此被視為未綁定的變數。當我們在 = 運算符的左側的元組 {X,Y} 中設定它們時,= 運算符會比較兩個值:{X,Y} 與 {4,5}。Erlang 很聰明,足以將元組中的值解包,並將它們分配給左側的未綁定變數。然後比較就只是 {4,5} = {4,5},這顯然會成功!這是模式匹配的許多形式之一。
請注意,在表達式 6 中,我使用了匿名變數 _。這正是它的使用方式:丟棄通常會放置在那裡的值,因為我們不會使用它。_ 變數始終被視為未綁定,並充當模式匹配的萬用字元。只有當元素的數量(元組的長度)相同時,解包元組的模式匹配才會起作用。
7> {_,_} = {4,5}.
{4,5}
8> {_,_} = {4,5,6}.
** exception error: no match of right hand side value {4,5,6}
當處理單一值時,元組也很有用。怎麼說呢?最簡單的例子是溫度
9> Temperature = 23.213. 23.213
嗯,聽起來是個去海灘的好日子…等等,這個溫度是開爾文、攝氏還是華氏?
10> PreciseTemperature = {celsius, 23.213}.
{celsius,23.213}
11> {kelvin, T} = PreciseTemperature.
** exception error: no match of right hand side value {celsius,23.213}
這會拋出錯誤,但這正是我們想要的!這又是模式匹配在起作用。= 運算符最終會比較 {kelvin, T} 和 {celsius, 23.213}:即使變數 T 未綁定,Erlang 在比較時也不會將 celsius 原子視為與 kelvin 原子相同。會拋出異常,這會停止程式碼的執行。這樣一來,我們程式中預期以開爾文為單位的溫度部分將無法處理以攝氏度發送的溫度。這使程式設計師更容易知道正在發送什麼,並且還可以作為除錯輔助工具。包含一個原子和一個跟隨其後的元素的元組稱為「標記元組」。元組的任何元素都可以是任何類型,甚至是另一個元組。
12> {point, {X,Y}}.
{point,{4,5}}
但如果我們想攜帶多個點呢?
列表!
列表是許多函數式語言的基礎。它們用於解決各種問題,並且無疑是 Erlang 中最常用的資料結構。列表可以包含任何內容!數字、原子、元組、其他列表;你最瘋狂的夢想都可以在單一的結構中實現。列表的基本表示法是 [Element1, Element2, ..., ElementN],而且你可以在其中混合多種類型的資料
1> [1, 2, 3, {numbers,[4,5,6]}, 5.34, atom].
[1,2,3,{numbers,[4,5,6]},5.34,atom]
很簡單,對吧?
2> [97, 98, 99]. "abc"
哎呀!這是 Erlang 中最令人討厭的事情之一:字串!字串是列表,而且符號完全相同!為什麼人們不喜歡它?因為這個
3> [97,98,99,4,5,6]. [97,98,99,4,5,6] 4> [233]. "é"
只有當至少其中一個數字不能同時代表字母時,Erlang 才會將數字列表列印為數字!Erlang 中沒有真正的字串!這無疑會在未來困擾你,你會因此而討厭這門語言。別絕望,因為還有其他方法可以寫字串,我們將在本章稍後看到。
不要喝太多 Kool-Aid
這就是為什麼你可能聽說過 Erlang 在字串操作方面很爛:它沒有像大多數其他語言那樣的內建字串類型。這是因為 Erlang 最初是電信公司創建和使用的語言。他們從未(或很少)使用字串,因此從未覺得有必要正式添加它們。然而,Erlang 在字串操作方面的許多不合理之處正在隨著時間的推移而得到修復:虛擬機器現在原生支援 Unicode 字串,而且在字串操作方面整體上變得越來越快。
還有一種方法可以將字串儲存為二進位資料結構,使其非常輕巧且處理速度更快。總而言之,標準函式庫中仍然缺少一些函數,雖然在 Erlang 中肯定可以進行字串處理,但對於需要大量字串處理的任務來說,有一些更好的語言,例如 Perl 或 Python。
要將列表黏合在一起,我們使用 ++ 運算符。++ 的反面是 --,它會從列表中移除元素
5> [1,2,3] ++ [4,5]. [1,2,3,4,5] 6> [1,2,3,4,5] -- [1,2,3]. [4,5] 7> [2,4,2] -- [2,4]. [2] 8> [2,4,2] -- [2,4,2]. []
++ 和 -- 都是右結合的。這意味著許多 -- 或 ++ 運算的元素將從右到左執行,如下列範例所示
9> [1,2,3] -- [1,2] -- [3]. [3] 10> [1,2,3] -- [1,2] -- [2]. [2,3]
讓我們繼續。列表的第一個元素稱為頭 (Head),列表的其餘部分稱為尾 (Tail)。我們將使用兩個內建函數 (BIF) 來取得它們。
11> hd([1,2,3,4]). 1 12> tl([1,2,3,4]). [2,3,4]
注意:內建函數 (BIF) 通常是無法在純 Erlang 中實作的函數,因此在 C 或 Erlang 恰好實作在其上的任何語言(在 80 年代是 Prolog)中定義。仍然有一些 BIF 可以在 Erlang 中完成,但為了提高常見操作的速度,仍然在 C 中實作。其中一個例子是 length(List) 函數,它會傳回作為參數傳入的列表的長度(你猜到了)。
存取或新增頭是快速而有效的:幾乎所有需要處理列表的應用程式都會始終先對頭進行操作。由於它使用頻率如此之高,因此有一種更好的方法可以借助模式匹配來將列表的頭與尾分開:[Head|Tail]。這是你會如何向列表中新增一個新頭
13> List = [2,3,4]. [2,3,4] 14> NewList = [1|List]. [1,2,3,4]
當處理列表時,由於你通常從頭開始,你會希望有一種快速的方法來儲存尾部,以便稍後對其進行操作。如果你記得元組的工作方式,以及我們如何使用模式匹配來解包點 ({X,Y}) 的值,你就會知道我們可以透過類似的方式取得從列表中切出來的第一個元素(頭)。
15> [Head|Tail] = NewList. [1,2,3,4] 16> Head. 1 17> Tail. [2,3,4] 18> [NewHead|NewTail] = Tail. [2,3,4] 19> NewHead. 2
我們使用的 | 稱為 cons 運算符(建構子)。事實上,任何列表都可以僅使用 cons 和值來建構
20> [1 | []]. [1] 21> [2 | [1 | []]]. [2,1] 22> [3 | [2 | [1 | []] ] ]. [3,2,1]
這就是說,任何列表都可以用以下公式建構:[Term1| [Term2 | [... | [TermN]]]]...。因此,列表可以遞迴地定義為一個頭部接續一個尾部,而尾部本身又是另一個頭部後面接續更多的頭部。從這個意義上講,我們可以想像列表有點像蚯蚓:你可以將它切成兩半,然後你會得到兩條蚯蚓。

Erlang 列表的建構方式有時會讓不習慣類似建構子的人感到困惑。為了幫助你熟悉這個概念,請閱讀所有這些範例(提示:它們都是等效的)
[a, b, c, d] [a, b, c, d | []] [a, b | [c, d]] [a, b | [c | [d]]] [a | [b | [c | [d]]]] [a | [b | [c | [d | [] ]]]]
理解了這些,你就應該能夠處理列表推導式了。
注意:使用 [1 | 2] 的形式會給出我們所謂的「不正確的列表」。當你在 [Head|Tail] 方式中進行模式匹配時,不正確的列表會起作用,但無法與 Erlang 的標準函數(甚至是 length())一起使用。這是因為 Erlang 期望正確的列表。正確的列表以空列表作為其最後一個單元格結束。當宣告像 [2] 這樣的項目時,列表會以正確的方式自動形成。因此,[1|[2]] 可以運作!不正確的列表雖然在語法上有效,但在使用者定義的資料結構之外的用途非常有限。
列表推導式
列表推導式是建構或修改列表的方法。與其他操縱列表的方法相比,它們還可以讓程式簡短且易於理解。它基於集合符號的思想;如果你曾經上過集合論的數學課,或者你曾經看過數學符號,你可能就知道它是如何運作的。集合符號基本上會透過指定其成員必須滿足的屬性來告訴你如何建構一個集合。列表推導式一開始可能很難掌握,但它們值得努力。它們會使程式碼更乾淨、更簡短,因此請不要猶豫,嘗試輸入範例,直到你理解它們為止!
集合符號的一個範例是 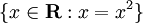 。該集合符號告訴你,你想要的結果將是所有等於其自身平方的實數。該集合的結果將是 {0,1}。另一個更簡單且縮寫的集合符號範例是
。該集合符號告訴你,你想要的結果將是所有等於其自身平方的實數。該集合的結果將是 {0,1}。另一個更簡單且縮寫的集合符號範例是 {x : x > 0}。在這裡,我們想要的是所有 x > 0 的數字。
Erlang 中的列表推導式是關於從其他集合建構集合。給定集合 {2n : n in L},其中 L 是列表 [1,2,3,4],Erlang 的實作將是
1> [2*N || N <- [1,2,3,4]]. [2,4,6,8]
將數學符號與 Erlang 符號進行比較,你會發現沒有太多改變:括號 ({}) 變成了方括號 ([]),冒號 (:) 變成了兩個豎線 (||),而單字 'in' 變成了箭頭 (<-)。我們只更改符號,並保持相同的邏輯。在上面的範例中,[1,2,3,4] 的每個值都會依序與 N 進行模式匹配。箭頭的作用與 = 運算符完全相同,但它不會拋出例外。
你也可以透過使用傳回布林值的運算來將約束新增到列表推導式中。如果我們想要一到十之間的所有偶數,我們可以寫成類似這樣的形式
2> [X || X <- [1,2,3,4,5,6,7,8,9,10], X rem 2 =:= 0]. [2,4,6,8,10]
其中 X rem 2 =:= 0 會檢查數字是否為偶數。當我們決定要將函數應用於列表的每個元素,強制其遵守約束等等時,就會出現實際應用。例如,假設我們擁有一家餐廳。一位顧客走進來,看到我們的菜單,並詢問是否可以提供所有價格在 3 美元到 10 美元之間的項目,並在之後計算稅金(例如 7%)。
3> RestaurantMenu = [{steak, 5.99}, {beer, 3.99}, {poutine, 3.50}, {kitten, 20.99}, {water, 0.00}].
[{steak,5.99},
{beer,3.99},
{poutine,3.5},
{kitten,20.99},
{water,0.0}]
4> [{Item, Price*1.07} || {Item, Price} <- RestaurantMenu, Price >= 3, Price =< 10].
[{steak,6.409300000000001},{beer,4.2693},{poutine,3.745}]
當然,小數點沒有以易於閱讀的方式四捨五入,但你明白了。因此,Erlang 中列表推導式的規則是 NewList = [Expression || Pattern <- List, Condition1, Condition2, ... ConditionN]。Pattern <- List 部分稱為產生器表達式。你可以有多個!
5> [X+Y || X <- [1,2], Y <- [2,3]]. [3,4,4,5]
這會執行運算 1+2、1+3、2+2 和 2+3。因此,如果您想讓列表推導式更加通用,您可以這樣寫:NewList = [Expression || GeneratorExp1, GeneratorExp2, ..., GeneratorExpN, Condition1, Condition2, ... ConditionM]。請注意,產生器表達式與模式匹配結合使用時,也具有過濾器的作用。
6> Weather = [{toronto, rain}, {montreal, storms}, {london, fog},
6> {paris, sun}, {boston, fog}, {vancouver, snow}].
[{toronto,rain},
{montreal,storms},
{london,fog},
{paris,sun},
{boston,fog},
{vancouver,snow}]
7> FoggyPlaces = [X || {X, fog} <- Weather].
[london,boston]
如果列表 'Weather' 中的某個元素不符合 {X, fog} 模式,它在列表推導式中會被簡單地忽略,而 = 運算符會拋出例外。
現在還有一個基本資料型態要介紹。這是一個令人驚訝的功能,它讓二進制資料的解析變得非常簡單。
位元語法!
大多數語言都支援操作數字、原子、元組、列表、記錄和/或結構等資料。它們大多數也只有非常原始的工具來操作二進制資料。Erlang 為了在使用二進制值時提供有用的抽象而做出了努力,將模式匹配提升到了新的層次。它使得處理原始二進制資料變得有趣且容易(真的),這對於它被創造出來以協助的電信應用來說是必要的。位元操作具有獨特的語法和慣用法,乍看之下可能有點奇怪,但如果您了解位元和位元組的基本運作方式,這應該對您來說是有意義的。**否則您可能想跳過本章的其餘部分。**
位元語法將二進制資料封裝在 << 和 >> 之間,將其分割成可讀的區段,每個區段以逗號分隔。一個區段是一個二進制資料的位元序列(不一定在位元組邊界上,儘管這是預設行為)。假設我們想要儲存一個真彩(24 位元)的橘色像素。如果您曾在 Photoshop 或網路 CSS 樣式表中檢查過顏色,您會知道十六進制表示法具有 #RRGGBB 的格式。橘色的陰影在該表示法中是 #F09A29,可以在 Erlang 中展開為
1> Color = 16#F09A29. 15768105 2> Pixel = <<Color:24>>. <<240,154,41>>
這基本上表示「將 #F09A29 的二進制值放在 24 位元的空間中(紅色佔 8 位元、綠色佔 8 位元,藍色也佔 8 位元),並存入變數 Pixel 中。」該值稍後可以被寫入檔案。這看起來不多,但一旦寫入檔案,您在文字編輯器中打開它會看到一堆無法讀取的字元。當您從檔案讀回時,Erlang 會將二進制資料再次解析成漂亮的 <<240,151,41>> 格式!
更有趣的是能夠使用二進制資料進行模式匹配來解壓縮內容
3> Pixels = <<213,45,132,64,76,32,76,0,0,234,32,15>>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
4> <<Pix1,Pix2,Pix3,Pix4>> = Pixels.
** exception error: no match of right hand side value <<213,45,132,64,76,32,76,
0,0,234,32,15>>
5> <<Pix1:24, Pix2:24, Pix3:24, Pix4:24>> = Pixels.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
我們在命令 3 中所做的是宣告二進制資料中確切的 4 個 RGB 色彩像素。
在表達式 4 中,我們試圖從二進制內容中解壓縮 4 個值。它拋出例外,因為我們有超過 4 個區段,事實上我們有 12 個!所以我們要做的是告訴 Erlang 左側的每個變數將保存 24 位元的資料。這就是 Var:24 的含義。然後我們可以取得第一個像素並將其進一步解壓縮為單獨的顏色值
6> <<R:8, G:8, B:8>> = <<Pix1:24>>. <<213,45,132>> 7> R. 213
「是啊,這很好。如果我只想從開頭取得第一個顏色怎麼辦?我需要一直解壓縮所有這些值嗎?」哈!不要懷疑!Erlang 引入了更多的語法糖和模式匹配來幫助您
8> <<R:8, Rest/binary>> = Pixels. <<213,45,132,64,76,32,76,0,0,234,32,15>> 9> R. 213
不錯吧?這是因為 Erlang 接受多種方式來描述二進制區段。這些都是有效的
Value Value:Size Value/TypeSpecifierList Value:Size/TypeSpecifierList
其中 Size 將代表位元或位元組(取決於下面的 Type 和 Unit),而 TypeSpecifierList 代表以下一個或多個
- 類型
- 可能的值:
integer | float | binary | bytes | bitstring | bits | utf8 | utf16 | utf32 - 這表示使用的二進制資料類型。請注意,'bytes' 是 'binary' 的簡寫,而 'bits' 是 'bitstring' 的簡寫。如果未指定類型,Erlang 會假設為 'integer' 類型。
- 符號
- 可能的值:
signed | unsigned - 僅當類型為整數時,匹配時才重要。預設值為 'unsigned'。
- 位元組順序
- 可能的值:
big | little | native - 位元組順序僅在類型為整數、utf16、utf32 或浮點數時才重要。這與系統如何讀取二進制資料有關。舉例來說,BMP 圖像標頭格式將其檔案大小保存為儲存在 4 個位元組上的整數。對於大小為 72 位元組的檔案,小端系統會將其表示為
<<72,0,0,0>>,而大端系統則會表示為<<0,0,0,72>>。一個將被讀取為「72」,而另一個將被讀取為「1207959552」,因此請確保您使用正確的位元組順序。還有一個選項可以使用「native」,它會在執行時選擇 CPU 本機使用小端或大端位元組順序。預設情況下,位元組順序設定為「big」。 - 單位
- 寫作
unit:Integer - 這是每個區段的大小,以位元為單位。允許的範圍是 1..256,對於整數、浮點數和位元字串,預設設定為 1,對於二進制資料,預設設定為 8。utf8、utf16 和 utf32 類型不需要定義單位。大小乘以單位等於區段將佔用的位元數,並且必須能被 8 整除。單位大小通常用於確保位元組對齊。
TypeSpecifierList 是通過用「-」分隔屬性來建立的。
一些範例可能會有助於消化定義
10> <<X1/unsigned>> = <<-44>>. <<"Ô">> 11> X1. 212 12> <<X2/signed>> = <<-44>>. <<"Ô">> 13> X2. -44 14> <<X2/integer-signed-little>> = <<-44>>. <<"Ô">> 15> X2. -44 16> <<N:8/unit:1>> = <<72>>. <<"H">> 17> N. 72 18> <<N/integer>> = <<72>>. <<"H">> 19> <<Y:4/little-unit:8>> = <<72,0,0,0>>. <<72,0,0,0>> 20> Y. 72
您可以看到有不止一種方式可以讀取、儲存和解析二進制資料。這有點令人困惑,但仍然比大多數語言提供的常用工具簡單得多。
Erlang 中也存在標準的二進制運算(將位元向左和向右移動,二進制的 'and'、'or'、'xor' 或 'not')。只需使用函數 bsl(位元左移)、bsr(位元右移)、band、bor、bxor 和 bnot。
2#00100 = 2#00010 bsl 1. 2#00001 = 2#00010 bsr 1. 2#10101 = 2#10001 bor 2#00101.
有了這種表示法和一般的位元語法,解析和模式匹配二進制資料就輕而易舉了。可以使用如下程式碼解析 TCP 區段
<<SourcePort:16, DestinationPort:16, AckNumber:32, DataOffset:4, _Reserved:4, Flags:8, WindowSize:16, CheckSum: 16, UrgentPointer:16, Payload/binary>> = SomeBinary.
相同的邏輯可以應用於任何二進制資料:視訊編碼、圖像、其他協定實作等等。
不要喝太多 Kool-Aid
與 C 或 C++ 等語言相比,Erlang 速度較慢。除非您是一個有耐心的人,否則用它來做像是轉換視訊或圖像之類的事情會是一個糟糕的主意,即使如上所述,二進制語法讓它非常有趣。Erlang 在繁重數字運算方面表現不佳。
但是請注意,對於不需要數字運算的應用程式來說,Erlang 仍然非常快速:對事件做出反應、訊息傳遞(在原子非常輕量化的情況下)等等。它可以處理毫秒級的事件,因此是軟即時應用程式的絕佳選擇。
二進制表示法還有另一個方面:位元字串。位元字串像列表一樣被添加到語言之上,但在空間方面效率更高。這是因為普通列表是連結列表(每個字母 1 個「節點」),而位元字串更像是 C 陣列。位元字串使用語法 <<"this is a bit string!">>。與列表相比,二進制字串的缺點是在模式匹配和操作方面失去了簡單性。因此,人們傾向於在儲存不會被過多操作的文字或空間效率是一個實際問題時使用二進制字串。
注意:即使位元字串非常輕巧,您也應該避免使用它們來標記值。使用字串字面量來說 {<<"temperature">>,50} 可能很誘人,但執行此操作時請始終使用原子。在本章前面,原子據說無論長度如何都只佔用 4 或 8 個位元組的空間。透過使用它們,您在將資料從一個函數複製到另一個函數或將其傳送到另一個伺服器上的另一個 Erlang 節點時,基本上不會有任何開銷。
相反,不要使用原子來取代字串,因為它們更輕。字串可以被操作(分割、正規表示式等等),而原子只能被比較,不能做其他任何事情。
二進制推導式
二進制推導式對於位元語法來說,就像列表推導式對於列表一樣:一種使程式碼簡短而簡潔的方式。它們在 Erlang 世界中相對較新,因為它們在以前的 Erlang 修訂版中就存在,但需要一個模組來實作它們,才能使用特殊的編譯標誌來運作。自 R13B 修訂版(此處使用的版本)以來,它們已成為標準,可以在任何地方使用,包括 Shell
1> [ X || <<X>> <= <<1,2,3,4,5>>, X rem 2 == 0]. [2,4]
與常規列表推導式相比,語法上的唯一變化是 <- 變成了 <=,以及使用二進制資料 (<<>>) 而不是列表 ([])。在本章前面,我們看到了一個範例,其中有一個包含許多像素的二進制值,我們使用模式匹配來獲取每個像素的 RGB 值。它還不錯,但在較大的結構上,它可能會變得更難讀取和維護。相同的練習可以使用單行二進制推導式來完成,這會更清晰
2> Pixels = <<213,45,132,64,76,32,76,0,0,234,32,15>>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
3> RGB = [ {R,G,B} || <<R:8,G:8,B:8>> <= Pixels ].
[{213,45,132},{64,76,32},{76,0,0},{234,32,15}]
將 <- 變更為 <= 可以讓我們使用二進制流作為產生器。完整的二進制推導式基本上將二進制資料變更為元組中的整數。存在另一個二進制推導式語法,讓您可以執行完全相反的操作
4> << <<R:8, G:8, B:8>> || {R,G,B} <- RGB >>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
請小心,因為如果產生器傳回二進制資料,則產生的二進制資料的元素需要有明確定義的大小
5> << <<Bin>> || Bin <- [<<3,7,5,4,7>>] >>. ** exception error: bad argument 6> << <<Bin/binary>> || Bin <- [<<3,7,5,4,7>>] >>. <<3,7,5,4,7>>
在滿足上述固定大小規則的前提下,也可以使用具有二進制產生器的二進制推導式
7> << <<(X+1)/integer>> || <<X>> <= <<3,7,5,4,7>> >>. <<4,8,6,5,8>>
注意:在撰寫本文時,二進制推導式很少使用,並且沒有很好的文件記錄。因此,我們決定只深入研究到足以識別它們並理解它們的基本工作方式。要更全面地理解位元語法,請閱讀定義其規格的白皮書。