應用程式計數
從 OTP 應用程式到實際應用程式
我們的 ppool 應用程式已成為有效的 OTP 應用程式,現在我們能夠理解這意味著什麼。不過,如果能建立一些真正利用我們的程序池來做有用的事情,那就太好了。為了更深入了解應用程式,我們將編寫第二個應用程式。這個應用程式將依賴 ppool,但將能夠從比我們的「嘮叨鬼」更多的自動化中獲益。
我將這個應用程式命名為 erlcount,它將有一個相對簡單的目標:遞迴地查看一些目錄,找到所有 Erlang 檔案(以 .erl 結尾),然後在其中執行正規表示式,以計算模組中給定字串的所有實例。然後將結果累積以得出最終結果,該結果將輸出到螢幕上。
這個特定的應用程式將相對簡單,主要依賴我們的程序池。它的結構如下
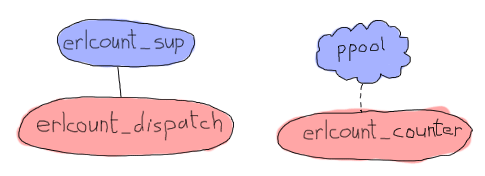
在上圖中,ppool 代表整個應用程式,但僅表示 erlcount_counter 將成為程序池的工作者。這個工作者將開啟檔案、執行正規表示式並傳回計數。程序/模組 erlcount_sup 將是我們的監管者,而 erlcount_dispatch 將是一個單一伺服器,負責瀏覽目錄、要求 ppool 排程工作者以及編譯結果。我們還將新增一個 erlcount_lib 模組,負責託管所有讀取目錄、編譯資料等等的功能,而將協調這些呼叫的責任留給其他模組。最後是一個 erlcount 模組,其唯一目的是作為應用程式回呼模組。
和我們上一個應用程式一樣,第一步是建立所需的目錄結構。您也可以隨意新增一些檔案存根
ebin/ - erlcount.app include/ priv/ src/ - erlcount.erl - erlcount_counter.erl - erlcount_dispatch.erl - erlcount_lib.erl - erlcount_sup.erl test/ Emakefile
和我們之前擁有的沒有太大的不同,您甚至可以複製我們之前擁有的 Emakefile。
我們可能可以很快開始編寫應用程式的大部分部分。 .app 檔案、計數器、程式庫和監管者應該相對簡單。另一方面,如果我們希望事情值得,分派模組將必須完成一些複雜的任務。讓我們從 app 檔案開始
{application, erlcount,
[{vsn, "1.0.0"},
{modules, [erlcount, erlcount_sup, erlcount_lib,
erlcount_dispatch, erlcount_counter]},
{applications, [ppool]},
{registered, [erlcount]},
{mod, {erlcount, []}},
{env,
[{directory, "."},
{regex, ["if\\s.+->", "case\\s.+\\sof"]},
{max_files, 10}]}
]}.
這個 app 檔案比 ppool 檔案複雜一點。我們仍然可以識別出某些欄位是相同的:這個 app 也將是 1.0.0 版,列出的模組與上面相同。下一部分是我們之前沒有的:應用程式相依性。如先前所述,applications 元組會提供一個清單,其中包含應在 erlcount 之前啟動的所有應用程式。如果您在沒有該清單的情況下嘗試啟動它,您會收到錯誤訊息。然後我們必須使用 {registered, [erlcount]} 來計算已註冊的程序。從技術上講,我們作為 erlcount app 一部分啟動的模組都不需要名稱。我們所做的一切都可以是匿名的。但是,因為我們知道 ppool 會將 ppool_serv 註冊到我們給它的名稱,而且因為我們知道我們將使用程序池,所以我們將它稱為 erlcount 並在此處記錄下來。如果所有使用 ppool 的應用程式都這麼做,我們應該能夠在未來偵測到衝突。mod 元組與之前類似;我們在此處定義應用程式行為回呼模組。

這裡最後的新事物是 env 元組。如先前所述,整個元組會提供一個金鑰/值儲存,用於儲存應用程式特定的組態變數。這些變數可以從應用程式內執行的所有程序存取,並儲存在記憶體中以便您使用。它們基本上可以用作您的應用程式的替代組態檔案。
在這種情況下,我們定義了三個變數:directory,它會告知 app 在哪裡尋找 .erl 檔案(假設我們從 erlcount-1.0 目錄執行 app,這表示 learn-you-some-erlang 根目錄),然後我們有 max_files,它會告知我們應該一次開啟多少個檔案描述元。如果我們最終開啟那麼多檔案,我們不想一次開啟 10,000 個檔案,因此此變數會符合 ppool 中的最大工作者數。然後最複雜的變數是 regex。這個變數會包含一個清單,其中包含我們想要在每個檔案上執行的所有正規表示式,以計算結果。
我不會詳細解釋 Perl 相容正規表示式的語法(如果您有興趣,re 模組包含一些文件),但仍然會解釋我們在這裡做的事情。在這種情況下,第一個正規表示式會說「尋找一個包含 'if' 的字串,後面接著任何單一空白字元 (\s,為了轉義目的而使用第二個反斜線),並以 -> 結尾。此外,在 'if' 和 -> 之間可以有任何內容 (.+)」。第二個正規表示式會說「尋找一個包含 'case' 的字串,後面接著任何單一空白字元 (\s),並以單一空白字元之前的 'of' 結尾。在 'case ' 和 ' of' 之間,可以有任何內容 (.+)」。為了簡化起見,我們將嘗試計算在我們的程式庫中使用 case ... of 的次數,與使用 if ... end 的次數相比。
不要喝太多酷愛飲料
使用正規表示式不是分析 Erlang 程式碼的最佳選擇。問題在於,許多情況會導致我們的結果不準確,包括文字中的字串和符合我們正在尋找的模式但技術上不是程式碼的註解。
為了獲得更準確的結果,我們需要直接在 Erlang 中查看模組的已剖析和展開版本。雖然更複雜(而且超出本文範圍),但這可以確保我們處理所有巨集、排除註解,而且總體而言是以正確的方式執行。
解決此檔案後,我們可以啟動 應用程式回呼模組。它不會很複雜,基本上只會啟動監管者
-module(erlcount).
-behaviour(application).
-export([start/2, stop/1]).
start(normal, _Args) ->
erlcount_sup:start_link().
stop(_State) ->
ok.
現在是 監管者本身
-module(erlcount_sup).
-behaviour(supervisor).
-export([start_link/0, init/1]).
start_link() ->
supervisor:start_link(?MODULE, []).
init([]) ->
MaxRestart = 5,
MaxTime = 100,
{ok, {{one_for_one, MaxRestart, MaxTime},
[{dispatch,
{erlcount_dispatch, start_link, []},
transient,
60000,
worker,
[erlcount_dispatch]}]}}.
這是一個標準監管者,它只會負責 erlcount_dispatch,如先前的簡圖所示。選擇 MaxRestart、MaxTime 和關閉的 60 秒值是相當隨機的,但在實際情況下,您會想要研究您擁有的需求。由於這是一個示範應用程式,因此當時似乎不那麼重要。作者保留了自己偷懶的權利。
我們可以進入鏈中的下一個程序和模組,即分派器。分派器必須滿足一些複雜的要求,才能使其有用
- 當我們瀏覽目錄以尋找以
.erl結尾的檔案時,即使我們應用多個正規表示式,我們也應該只瀏覽整個目錄清單一次; - 一旦我們發現有符合我們條件的檔案,我們應該能夠開始排程檔案以進行結果計數。我們不應該需要等待完整的清單才能這樣做。
- 我們需要為每個正規表示式保留一個計數器,以便我們在最後比較結果
- 我們有可能在我們完成尋找
.erl檔案之前,開始從erlcount_counter工作者取得結果 - 有可能許多
erlcount_counter會同時執行 - 我們很可能會在我們完成在目錄中查找檔案之後繼續取得結果(特別是當我們有許多檔案或複雜的正規表示式時)。
我們現在必須考慮的兩個重點是,我們將如何遞迴地瀏覽目錄,同時仍然能夠從那裡取得結果以排程它們,然後在該過程繼續進行時接收結果,而不會感到困惑。
乍看之下,在遞迴過程中能夠傳回結果的最簡單方法是使用程序來執行。然而,為了能夠在監管樹中新增另一個程序,然後讓它們一起工作,而改變我們先前的結構有點令人煩惱。事實上,有一種更簡單的方法可以做到這一點。
這是一種稱為接續傳遞樣式的程式設計風格。其背後的基礎概念是取得一個通常深度遞迴的函數,並分解每個步驟。我們傳回每個步驟(通常是累加器),然後傳回一個函數,該函數允許我們在那之後繼續。在我們的情況下,我們的函數基本上有兩個可能的傳回值
{continue, Name, NextFun}
done
每當我們收到第一個傳回值時,我們就可以將 FileName 排程到 ppool 中,然後呼叫 NextFun 以繼續尋找更多檔案。我們可以將此函數實作到 erlcount_lib 中
-module(erlcount_lib).
-export([find_erl/1]).
-include_lib("kernel/include/file.hrl").
%% Finds all files ending in .erl
find_erl(Directory) ->
find_erl(Directory, queue:new()).
啊,那裡有新的東西!真是個驚喜,我的心跳加速,血液沸騰。上面的 include 檔案是 file 模組提供給我們的東西。它包含一個記錄 (#file_info{}),其中包含一堆欄位,說明檔案的詳細資訊,包括其類型、大小、權限等等。
我們這裡的設計包含一個佇列。為什麼會這樣?好吧,一個目錄完全有可能包含多個檔案。因此,當我們命中一個目錄,並且它包含類似 15 個檔案的內容時,我們想要處理第一個檔案(如果它是目錄,則開啟它、查看內部等等),然後稍後處理其他 14 個檔案。為了這樣做,我們只會將它們的名稱儲存在記憶體中,直到我們有時間處理它們。我們為此使用佇列,但由於我們並不真正關心讀取檔案的順序,因此使用堆疊或任何其他資料結構仍然可以。無論如何,重點是,這個佇列的作用有點像我們演算法中檔案的待辦事項清單。
好吧,讓我們從讀取第一次呼叫傳遞的第一個檔案開始
%%% Private
%% Dispatches based on file type
find_erl(Name, Queue) ->
{ok, F = #file_info{}} = file:read_file_info(Name),
case F#file_info.type of
directory -> handle_directory(Name, Queue);
regular -> handle_regular_file(Name, Queue);
_Other -> dequeue_and_run(Queue)
end.
此函數告訴我們一些事情:我們只想要處理常規檔案和目錄。在每種情況下,我們都會為自己編寫一個函數來處理這些特定事件 (handle_directory/2 和 handle_regular_file/2)。對於其他檔案,我們將在 dequeue_and_run/1 的協助下,將我們之前準備好的任何內容出列(我們很快就會了解這一個是什麼)。現在,我們首先開始處理目錄
%% Opens directories and enqueues files in there
handle_directory(Dir, Queue) ->
case file:list_dir(Dir) of
{ok, []} ->
dequeue_and_run(Queue);
{ok, Files} ->
dequeue_and_run(enqueue_many(Dir, Files, Queue))
end.
因此,如果沒有檔案,我們會使用 dequeue_and_run/1 繼續搜尋,如果有很多檔案,我們會先將它們入列,然後再這樣做。讓我解釋一下。函數 dequeue_and_run 將取得檔案名稱佇列並從中取出一個元素。從那裡取出的檔案名稱將藉由呼叫 find_erl(Name, Queue) 來使用,而我們只是像剛開始一樣繼續進行
%% Pops an item from the queue and runs it.
dequeue_and_run(Queue) ->
case queue:out(Queue) of
{empty, _} -> done;
{{value, File}, NewQueue} -> find_erl(File, NewQueue)
end.
請注意,如果佇列為空 ({empty, _}),則函數會認為自己已 done(為我們的 CPS 函數選擇的關鍵字),否則我們會繼續重複。
我們必須考慮的另一個函數是 enqueue_many/3。此函數旨在將在給定目錄中找到的所有檔案入列,其運作方式如下
%% Adds a bunch of items to the queue.
enqueue_many(Path, Files, Queue) ->
F = fun(File, Q) -> queue:in(filename:join(Path,File), Q) end,
lists:foldl(F, Queue, Files).
基本上,我們使用 filename:join/2 函數將目錄路徑與每個檔案名稱合併(以便我們得到完整的路徑)。然後,我們將這個新的完整路徑添加到檔案佇列中。我們使用 fold 操作來對指定目錄中的所有檔案重複相同的程序。從中得到的新佇列隨後會再次用於執行 find_erl/2,但這次是將所有找到的新檔案添加到待辦事項清單中。
哇,我們有點離題了。我們剛才說到哪裡了?哦,對了,我們正在處理目錄,現在我們已經處理完了。接下來,我們需要檢查常規檔案,以及它們是否以 .erl 結尾。
%% Checks if the file finishes in .erl
handle_regular_file(Name, Queue) ->
case filename:extension(Name) of
".erl" ->
{continue, Name, fun() -> dequeue_and_run(Queue) end};
_NonErl ->
dequeue_and_run(Queue)
end.
你可以看到,如果名稱匹配(根據 filename:extension/1),我們會返回我們的 continuation。這個 continuation 會將 Name 提供給呼叫者,然後將 dequeue_and_run/1 操作與剩餘待訪問的檔案佇列包裝成一個函數。這樣,使用者就可以呼叫該函數並繼續執行,彷彿我們仍然在遞迴呼叫中,同時仍然能獲得結果。如果檔案名稱不是以 .erl 結尾,那麼使用者就沒有興趣讓我們立即返回,我們會繼續從佇列中取出更多的檔案來處理。就是這樣。
太棒了,CPS 的部分完成了。接下來我們可以專注於另一個問題。我們要如何設計這個分派器,使其可以同時分派和接收?我的建議是,你們一定會接受的,因為這篇文章是我寫的,就是使用有限狀態機。它將有兩種狀態。第一種是「分派」狀態。當我們等待 find_erl CPS 函數命中 done 條目時,就會使用這種狀態。當我們處於這種狀態時,我們永遠不會考慮計數是否完成。只有在第二個也是最後一個狀態「監聽」狀態才會考慮,但我們仍然會不斷收到來自 ppool 的通知。
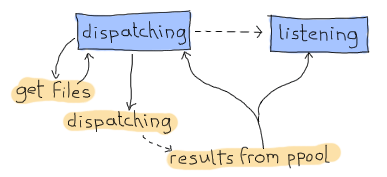
因此,這會要求我們有
- 一個分派狀態,帶有一個非同步事件,用於在我們收到要分派的新檔案時觸發
- 一個分派狀態,帶有一個非同步事件,用於在我們完成接收新檔案時觸發
- 一個監聽狀態,帶有一個非同步事件,用於在我們完成接收新檔案時觸發
- 一個全域事件,由 ppool 工作者在完成執行其正規表示式時發送。
我們將慢慢開始建構 我們的 gen_fsm
-module(erlcount_dispatch).
-behaviour(gen_fsm).
-export([start_link/0, complete/4]).
-export([init/1, dispatching/2, listening/2, handle_event/3,
handle_sync_event/4, handle_info/3, terminate/3, code_change/4]).
-define(POOL, erlcount).
因此,我們的 API 將有兩個函數:一個用於監督者(start_link/0),另一個用於 ppool 呼叫者(complete/4,當我們到達那裡時,我們會看到這些參數)。其他函數是標準的 gen_fsm 回呼函數,包括我們的 listening/2 和 dispatching/2 非同步狀態處理常式。我也定義了一個 ?POOL 巨集,用於將我們的 ppool 伺服器命名為 'erlcount'。
但是,gen_fsm 的資料應該是什麼樣子呢?由於我們是非同步的,並且我們將始終呼叫 ppool:run_async/2 而不是其他任何函數,因此我們無法真正知道我們是否已經完成排程檔案。基本上,我們可能會遇到如下的時間軸
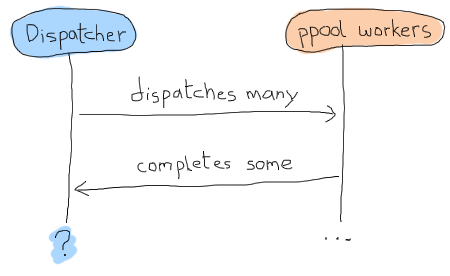
解決問題的一種方法是使用逾時,但這總是令人煩惱:逾時時間太長還是太短?是否發生了什麼崩潰?這種不確定性可能就像用檸檬做的牙刷一樣令人不快。相反,我們可以採用一個概念,為每個工作者提供某種身分識別,我們可以追蹤該身分識別並將其與回覆關聯,有點像進入「成功的工作者」私人俱樂部的秘密密碼。這個概念將讓我們可以一對一地匹配我們收到的任何訊息,並讓我們知道我們何時絕對完成。我們現在知道我們的狀態資料可能如下所示
-record(data, {regex=[], refs=[]}).
第一個清單將是 {RegularExpression, NumberOfOccurrences} 形式的元組,而第二個清單將是一些訊息參考的清單。任何東西都可以,只要它是唯一的即可。然後,我們可以新增以下兩個 API 函數
%%% PUBLIC API
start_link() ->
gen_fsm:start_link(?MODULE, [], []).
complete(Pid, Regex, Ref, Count) ->
gen_fsm:send_all_state_event(Pid, {complete, Regex, Ref, Count}).
這是我們秘密的 complete/4 函數。不出所料,工作者只需要傳回 3 個資料:他們正在執行的正規表示式、他們關聯的分數,以及上述的參考。太棒了,我們可以進入真正有趣的部分了!
init([]) ->
%% Move the get_env stuff to the supervisor's init.
{ok, Re} = application:get_env(regex),
{ok, Dir} = application:get_env(directory),
{ok, MaxFiles} = application:get_env(max_files),
ppool:start_pool(?POOL, MaxFiles, {erlcount_counter, start_link, []}),
case lists:all(fun valid_regex/1, Re) of
true ->
self() ! {start, Dir},
{ok, dispatching, #data{regex=[{R,0} || R <- Re]}};
false ->
{stop, invalid_regex}
end.
init 函數首先載入我們需要從應用程式檔案執行的所有資訊。完成後,我們計劃使用 erlcount_counter 作為回呼模組來啟動處理程序池。在真正開始之前的最後一步是確保所有正規表示式都有效。原因很簡單。如果我們現在不檢查它,那麼我們將不得不在其他地方新增錯誤處理呼叫。這很可能會在 erlcount_counter 工作者中。現在,如果它發生在那裡,我們現在必須定義當工作者因此而開始崩潰時,我們該怎麼辦等等。在啟動應用程式時處理它會更簡單。這是 valid_regex/1 函數
valid_regex(Re) ->
try re:run("", Re) of
_ -> true
catch
error:badarg -> false
end.
我們只嘗試在空字串上執行正規表示式。這不會花費任何時間,並讓 re 模組嘗試執行操作。因此,正規表示式是有效的,我們透過向自己發送 {start, Directory} 和以 [{R,0} || R <- Re] 定義的狀態來啟動應用程式。這基本上會將 [a,b,c] 形式的清單變更為 [{a,0},{b,0},{c,0}] 形式,這樣做的目的是為每個正規表示式新增計數器。
我們必須處理的第一個訊息是 handle_info/2 中的 {start, Dir}。請記住,由於 Erlang 的行為幾乎都基於訊息,因此我們必須執行醜陋的步驟,向自己發送訊息,如果我們想觸發函數呼叫並按照我們的方式執行操作。這很煩人,但可以處理
handle_info({start, Dir}, State, Data) ->
gen_fsm:send_event(self(), erlcount_lib:find_erl(Dir)),
{next_state, State, Data}.
我們將 erlcount_lib:find_erl(Dir) 的結果發送給自己。它將在 dispatching 中收到,因為這是 State 的值,它是由 FSM 的 init 函數設定的。此程式碼片段解決了我們的問題,但也說明了我們在整個 FSM 期間將採用的通用模式。由於我們的 find_erl/1 函數是以 Continuation-Passing Style 撰寫的,因此我們可以僅向自己發送一個非同步事件,並在每個正確的回呼狀態中處理它。我們的 continuation 的第一個結果很可能是 {continue, File, Fun}。我們也會處於 'dispatching' 狀態,因為這就是我們在 init 函數中設定的初始狀態
dispatching({continue, File, Continuation}, Data = #data{regex=Re, refs=Refs}) ->
F = fun({Regex, _Count}, NewRefs) ->
Ref = make_ref(),
ppool:async_queue(?POOL, [self(), Ref, File, Regex]),
[Ref|NewRefs]
end,
NewRefs = lists:foldl(F, Refs, Re),
gen_fsm:send_event(self(), Continuation()),
{next_state, dispatching, Data#data{refs = NewRefs}};
這有點醜陋。對於每個正規表示式,我們都會建立一個唯一的參考,排程一個知道此參考的 ppool 工作者,然後儲存此參考(以了解工作者是否已完成)。我選擇在 foldl 中執行此操作,以便更輕鬆地累加所有新的參考。完成分派後,我們會再次呼叫 continuation 以取得更多結果,然後等待下一個訊息,並將新參考作為我們的狀態。
我們可以收到的下一個訊息是什麼?我們在這裡有兩個選擇。要麼沒有任何工作者將結果傳回給我們(即使它們尚未實作),要麼我們收到 done 訊息,因為所有檔案都已查找完畢。讓我們使用第二種類型來完成實作 dispatching/2 函數
dispatching(done, Data) ->
%% This is a special case. We can not assume that all messages have NOT
%% been received by the time we hit 'done'. As such, we directly move to
%% listening/2 without waiting for an external event.
listening(done, Data).
註解非常明確地說明了正在發生的事情,但讓我還是解釋一下。當我們排程工作時,我們可以在 dispatching/2 中或在 listening/2 中接收結果。這可以採用以下形式
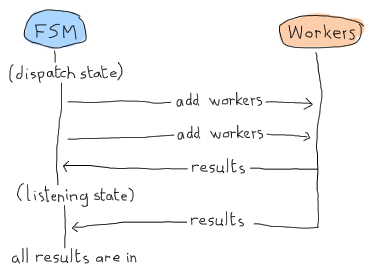
在這種情況下,'listening' 狀態可以只等待結果,並宣告一切都已完成。但請記住,這裡是 Erlang Land(Erland),我們以平行和非同步方式工作!這個情境也很有可能發生
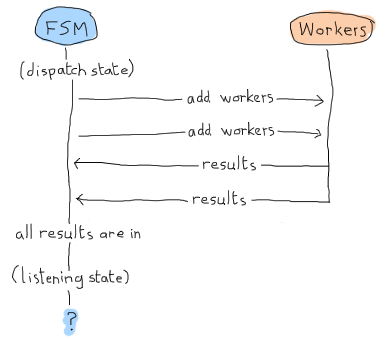
哎呀。我們的應用程式將永遠掛起,等待訊息。這就是我們需要手動呼叫 listening/2 的原因:我們將強制它執行某種結果偵測,以確保已收到所有內容,以防萬一我們已經擁有所有結果。這是它的樣子
listening(done, #data{regex=Re, refs=[]}) -> % all received!
[io:format("Regex ~s has ~p results~n", [R,C]) || {R, C} <- Re],
{stop, normal, done};
listening(done, Data) -> % entries still missing
{next_state, listening, Data}.
如果沒有剩餘的 refs,則已收到所有內容,我們可以輸出結果。否則,我們可以繼續監聽訊息。如果你再看看 complete/4 和這個圖表
結果訊息是全域的,因為它們可以在 'dispatching' 或 'listening' 狀態中接收。這是實作方式
handle_event({complete, Regex, Ref, Count}, State, Data = #data{regex=Re, refs=Refs}) ->
{Regex, OldCount} = lists:keyfind(Regex, 1, Re),
NewRe = lists:keyreplace(Regex, 1, Re, {Regex, OldCount+Count}),
NewData = Data#data{regex=NewRe, refs=Refs--[Ref]},
case State of
dispatching ->
{next_state, dispatching, NewData};
listening ->
listening(done, NewData)
end.
它執行的第一件事是在 Re 清單中找到剛完成的正規表示式,其中也包含所有正規表示式的計數。我們使用 lists:keyreplace/4 擷取該值 (OldCount) 並使用新計數 (OldCount+Count) 更新它。我們使用新分數更新我們的 Data 記錄,同時移除工作者的 Ref,然後將自己發送到下一個狀態。
在一般的 FSM 中,我們只會執行 {next_state, State, NewData},但是在這裡,由於提到我們知道何時完成的問題,我們必須手動再次呼叫 listening/2。真痛苦,但唉,這是必要的步驟。
分派器到此結束。我們只需新增其餘的填充行為函數
handle_sync_event(Event, _From, State, Data) ->
io:format("Unexpected event: ~p~n", [Event]),
{next_state, State, Data}.
terminate(_Reason, _State, _Data) ->
ok.
code_change(_OldVsn, State, Data, _Extra) ->
{ok, State, Data}.
然後我們可以繼續處理計數器。你可能想先稍作休息。硬核讀者可以先做幾下臥推來放鬆一下,然後再回來繼續閱讀。
計數器
計數器比分派器簡單。雖然我們仍然需要一個行為來執行操作(在這種情況下,是 gen_server),但它會相當簡潔。我們只需要它做三件事
- 開啟檔案
- 在其上執行正規表示式並計算實例
- 傳回結果。
對於第一點,我們在 file 中有許多函數可以幫助我們執行此操作。對於第 3 點,我們定義了 erlcount_dispatch:complete/4 來執行此操作。對於第 2 點,我們可以將 re 模組與 run/2-3 一起使用,但它無法完全執行我們需要的操作
1> re:run(<<"brutally kill your children (in Erlang)">>, "a").
{match,[{4,1}]}
2> re:run(<<"brutally kill your children (in Erlang)">>, "a", [global]).
{match,[[{4,1}],[{35,1}]]}
3> re:run(<<"brutally kill your children (in Erlang)">>, "a", [global, {capture, all, list}]).
{match,[["a"],["a"]]}
4> re:run(<<"brutally kill your children (in Erlang)">>, "child", [global, {capture, all, list}]).
{match,[["child"]]}
雖然它確實採用了我們需要的參數(re:run(String, Pattern, Options)),但它沒有提供我們正確的計數。讓我們將以下函數新增到 erlcount_lib 中,以便我們可以開始撰寫計數器
regex_count(Re, Str) ->
case re:run(Str, Re, [global]) of
nomatch -> 0;
{match, List} -> length(List)
end.
這個基本上只是計算結果並回傳。別忘了把它加入到匯出表單中。
好的,接著來看worker(工作者)
-module(erlcount_counter).
-behaviour(gen_server).
-export([start_link/4]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
terminate/2, code_change/3]).
-record(state, {dispatcher, ref, file, re}).
start_link(DispatcherPid, Ref, FileName, Regex) ->
gen_server:start_link(?MODULE, [DispatcherPid, Ref, FileName, Regex], []).
init([DispatcherPid, Ref, FileName, Regex]) ->
self() ! start,
{ok, #state{dispatcher=DispatcherPid,
ref = Ref,
file = FileName,
re = Regex}}.
handle_call(_Msg, _From, State) ->
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info(start, S = #state{re=Re, ref=Ref}) ->
{ok, Bin} = file:read_file(S#state.file),
Count = erlcount_lib:regex_count(Re, Bin),
erlcount_dispatch:complete(S#state.dispatcher, Re, Ref, Count),
{stop, normal, S}.
terminate(_Reason, _State) ->
ok.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
這裡兩個有趣的部分是 init/1 回呼函式,我們在此設定自身啟動,然後是單一的 handle_info/2 子句,我們在此開啟檔案(file:read_file(Name)),取得一個二進制資料,並將其傳遞給新的 regex_count/2 函式,然後用 complete/4 將其送回。接著我們停止 worker。剩下的只是標準的 OTP 回呼函式相關內容。
現在我們可以編譯並執行整個程式了!
$ erl -make Recompile: src/erlcount_sup Recompile: src/erlcount_lib Recompile: src/erlcount_dispatch Recompile: src/erlcount_counter Recompile: src/erlcount Recompile: test/erlcount_tests
太棒了。開香檳慶祝,因為我們沒有遇到任何問題!
執行應用程式
有很多方式可以執行我們的應用程式。請確保您在一個目錄中,其中兩個目錄以某種方式並排存在。
erlcount-1.0 ppool-1.0
現在用以下方式啟動 Erlang
$ erl -env ERL_LIBS "."
ERL_LIBS 變數是您環境中定義的一個特殊變數,可讓您指定 Erlang 在哪裡可以找到 OTP 應用程式。虛擬機器接著能夠自動在那裡搜尋 ebin/ 目錄。erl 也可以接受 -env NameOFVar Value 形式的參數來快速覆寫此設定,這就是我這裡使用的方式。ERL_LIBS 變數相當有用,尤其是在安裝函式庫時,所以請盡量記住它!
使用我們啟動的虛擬機器,我們可以測試模組是否都在那裡
1> application:load(ppool). ok
如果可以找到,此函式會嘗試將所有應用程式模組載入記憶體中。如果您不呼叫它,當應用程式啟動時會自動執行,但這提供了一種簡單的方法來測試我們的路徑。我們可以啟動應用程式
2> application:start(ppool), application:start(erlcount). ok Regex if\s.+-> has 20 results Regex case\s.+\sof has 26 results
您的結果可能會因您目錄中的內容而異。請注意,根據您擁有的檔案數量,這可能需要更長的時間。

但是,如果我們希望為應用程式設定不同的變數呢?我們需要一直更改應用程式檔案嗎? 不,我們不需要!Erlang 也支援這點。所以假設我想知道 Erlang 程式設計人員在他們的原始碼檔案中生氣了多少次?
erl 可執行檔支援 -AppName Key1 Val1 Key2 Val2 ... KeyN ValN 形式的一組特殊參數。在這種情況下,我們可以用以下兩個正規表達式,對 R14B02 發行版的 Erlang 原始碼執行以下正規表達式
$ erl -env ERL_LIBS "." -erlcount directory '"/home/ferd/otp_src_R14B02/lib/"' regex '["shit","damn"]' ... 1> application:start(ppool), application:start(erlcount). ok Regex shit has 3 results Regex damn has 1 results 2> q(). ok
請注意,在這種情況下,我作為參數提供的所有表達式都用單引號 (') 包裹。那是因為我希望它們被我的 Unix shell 按字面意思理解。不同的 shell 可能有不同的規則。
我們也可以嘗試使用更通用的表達式(允許值以大寫字母開頭)以及允許更多檔案描述子的方式進行搜尋
$ erl -env ERL_LIBS "." -erlcount directory '"/home/ferd/otp_src_R14B02/lib/"' regex '["[Ss]hit","[Dd]amn"]' max_files 50 ... 1> application:start(ppool), application:start(erlcount). ok Regex [Ss]hit has 13 results Regex [Dd]amn has 6 results 2> q(). ok
哦,OTP 程式設計師們。是什麼讓你們如此生氣?(「使用 Erlang」不是一個可接受的答案)
由於需要對數百個檔案進行更複雜的檢查,這可能需要更長的時間才能執行。這一切都運作良好,但有一些令人惱火的事情。為什麼我們總是手動啟動兩個應用程式?有沒有更好的方法?
包含的應用程式
包含的應用程式是讓程式運作的方式之一。包含應用程式的基本概念是將一個應用程式(在此例中為 ppool)定義為另一個應用程式(這裡為 erlcount)的一部分。為此,需要對兩個應用程式進行一些更改。
重點是您稍微修改應用程式檔案,然後需要為它們添加所謂的啟動階段等等。

越來越多人建議不要使用包含的應用程式,原因很簡單:它們嚴重限制了程式碼的重複使用。這樣想吧。我們花了很多時間研究 ppool 的架構,使其可以讓任何人使用,獲得自己的池,並自由地使用它做任何他們想做的事情。如果我們要將其推入包含的應用程式中,那麼它就不能再包含在此虛擬機器上的任何其他應用程式中,而且如果 erlcount 崩潰,那麼 ppool 也會被連帶關閉,破壞任何想使用 ppool 的第三方應用程式的工作。
由於這些原因,包含的應用程式通常會從許多 Erlang 程式設計師的工具箱中排除。正如我們在下一章看到的,發行版基本上可以幫助我們以更通用的方式做同樣的事情(以及更多)。
在那之前,我們還有一個關於應用程式的議題要討論。
複雜的終止
在某些情況下,我們需要在終止應用程式之前執行更多步驟。應用程式回呼模組中的 stop/1 函式可能不夠用,特別是因為它是在應用程式已經終止之後才被呼叫的。如果我們需要在應用程式實際消失之前清理東西,我們該怎麼辦?
訣竅很簡單。只需在您的應用程式回呼模組中加入一個 prep_stop(State) 函式。State 將是您的 start/2 函式傳回的狀態,而 prep_stop/1 傳回的任何內容都將傳遞給 stop/1。因此,函式 prep_stop/1 在技術上將自己插入 start/2 和 stop/1 之間,並在您的應用程式仍在運作時執行,但就在它關閉之前。
這種類型的回呼函式您會在需要使用它時才知道,但我們現在的應用程式不需要它。
不要喝太多 Kool-Aid
當我幫助 Yurii Rashkosvkii (yrashk) 偵錯 agner(Erlang 的套件管理器)的問題時,我想到了 prep_stop/1 回呼函式的真實世界用例。遇到的問題有點複雜,與 simple_one_for_one 監管者和應用程式主控者之間的奇怪互動有關,所以請隨意跳過這部分文字。
Agner 的基本結構是,應用程式啟動時,會啟動一個頂層監管者,該監管者會啟動一個伺服器和另一個監管者,而該監管者又會產生動態子進程。
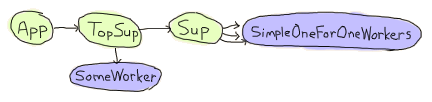
現在的問題是,文件上說了以下內容
關於 simple-one-for-one 監管者的重要注意事項:simple-one-for-one 監管者動態建立的子進程不會被明確終止,無論關閉策略為何,而是預期會在監管者終止時終止(也就是當收到來自父進程的退出訊號時)。
事實上它們確實沒有被終止。監管者只會終止其常規子進程,然後消失,讓 simple-one-for-one 子進程的行為來捕獲退出訊息並離開。單獨來說,這沒問題。
如前所述,對於每個應用程式,我們都有一個應用程式主控者。這個應用程式主控者充當組領導者。提醒一下,應用程式主控者會連結到其父項(應用程式控制器)及其直接子項(應用程式的頂層監管者),並監視它們兩者。當它們中的任何一個失敗時,主控者會終止自己的執行,使用其作為組領導者的身份來終止所有剩餘的子進程。同樣,單獨來說,這也沒問題。
然而,如果您將這兩個功能混合在一起,然後決定使用 application:stop(agner) 關閉應用程式,您最終會陷入非常麻煩的情況
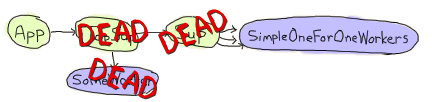
在這一確切的時間點,兩個監管者都已死亡,以及應用程式中的常規 worker。simple-one-for-one worker 目前正在死亡,每個 worker 都會捕獲其直接祖先發送的 EXIT 訊號。
但是,與此同時,應用程式主控者會發現其直接子項正在死亡,並最終殺死每一個尚未死亡的 simple-one-for-one worker。
結果是一堆設法自行清理的 worker,以及一堆沒有設法清理的 worker。這高度依賴於時間,很難偵錯,但很容易修復。
Yurii 和我基本上透過使用 ApplicationCallback:prep_stop(State) 函式來解決這個問題,以獲取所有動態 simple-one-for-one 子進程的列表,監視它們,然後等待它們全部在 stop(State) 回呼函式中死亡。這會強制應用程式控制器保持運作,直到所有動態子進程都死亡為止。您可以在 Agner 的 github 儲存庫中查看實際檔案。

真是個醜陋的東西!希望人們很少遇到這種問題,而且您也希望不會遇到。您可以往眼睛裡放一些肥皂,以洗去使用 prep_stop/1 來讓事情運作的糟糕畫面,即使它有時有意義且是可取的。當您回來時,我們將開始考慮將應用程式打包成發行版。
更新
自 R15B 版本以來,上述問題已解決。在監管者關閉的情況下,動態子進程的終止似乎是同步的。