Distribunomicon
獨自身處黑暗
嗨!請坐。我一直在等您。當您第一次聽到 Erlang 時,可能會有兩三個特性吸引您。Erlang 是一種函數式語言,它具有很棒的並發語義,並且支援分散式。我們現在已經看到了前兩個特性,花時間探索了十幾個您可能沒想到的特性,而現在我們來到了最後一個大重點,分散式。
我們等待了相當長的時間才來到這裡,因為如果我們無法首先在本地端讓事情正常運作,分散式就不是那麼有用。我們終於可以勝任這項任務,並且走了很長的路才到達這裡。像 Erlang 的幾乎所有其他特性一樣,該語言的分散式層最初是為了提供容錯能力而添加的。在單一機器上運行的軟體始終存在該單一機器死機並導致您的應用程式離線的風險。在多台機器上運行的軟體可以更容易地處理硬體故障,前提是應用程式的建置是正確的。如果您的應用程式在多台伺服器上運行,但無法處理其中一台伺服器被關閉的情況,則確實沒有任何關於容錯的好處。

你看,分散式程式設計就像獨自一人在黑暗中,到處都是怪物。這很可怕,你不知道該怎麼做,也不知道有什麼會攻擊你。壞消息:分散式 Erlang 仍然讓您獨自一人在黑暗中與可怕的怪物戰鬥。它不會為您做任何這類艱苦的工作。好消息:Erlang 不是讓您孤身一人,只有口袋零錢和糟糕的瞄準能力來殺死怪物,而是給您一個手電筒、一把彎刀,以及一個非常棒的鬍子,讓您感覺更有自信(這也適用於女性讀者)。
這並非特別是因為 Erlang 的撰寫方式,而或多或少是因為分散式軟體的本質。Erlang 將編寫分散式的幾個基本建構區塊:讓許多節點(虛擬機器)彼此通信的方式、通信中序列化和反序列化資料的方式、將多個進程的概念擴展到多個節點、監控網路故障的方式等等。然而,它不會為軟體特定的問題提供解決方案,例如「當東西崩潰時會發生什麼」。
這是之前在 OTP 中看到的標準「工具,而不是解決方案」方法;您很少獲得完整的軟體和應用程式,但您會獲得許多組件來構建系統。您將擁有在系統的某些部分啟動或關閉時告知您的工具、透過網路執行大量操作的工具,但幾乎沒有可以為您修復問題的萬能方法。
讓我們看看我們可以用這些工具做什麼樣的彈性處理。
這是我的 Boomstick
為了應對黑暗中的所有這些怪物,我們被賦予了一個非常有用的東西:相當完整的網路透明度。
正在啟動並運行,準備連接到其他虛擬機器的 Erlang 虛擬機器實例稱為節點。儘管某些語言或社群會將伺服器視為節點,但在 Erlang 中,每個 VM 都是一個節點。因此,您可以在一台電腦上運行 50 個節點,也可以在 50 台電腦上運行 50 個節點。這其實並不重要。
當您啟動一個節點時,您會給它一個名稱,它會連接到一個名為 EPMD 的應用程式(Erlang Port Mapper Daemon),該應用程式將在屬於您 Erlang 叢集的每台電腦上運行。EPMD 將充當名稱伺服器,讓節點註冊自己、聯絡其他節點,並在有任何名稱衝突時警告您。
從此時起,節點可以決定建立與另一個節點的連線。當它這樣做時,兩個節點都會自動開始互相監控,它們可以知道連線是否中斷,或者節點是否消失。更重要的是,當一個新節點加入已經連接在一起的一組節點中的另一個節點時,新節點會連接到整個群組。
讓我們以殭屍爆發期間的一群倖存者的想法來說明 Erlang 節點如何建立連線。我們有 Zoey、Bill、Rick 和 Daryl。Zoey 和 Bill 互相認識,並在無線對講機上的相同頻率上進行通信。Rick 和 Daryl 各自獨立。
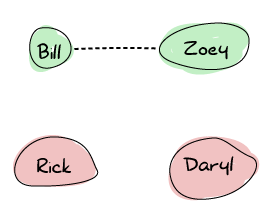
現在假設 Rick 和 Daryl 在前往倖存者營地的途中相遇。他們共享他們的無線對講機頻率,現在可以在再次分道揚鑣之前保持彼此的最新消息。
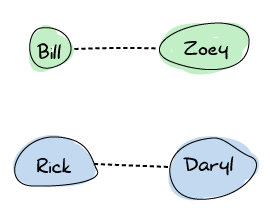
在某個時候,Rick 遇到了 Bill。兩人都對此感到非常高興,因此他們決定共享頻率。此時,連線擴散,最終圖表現在看起來像這樣。
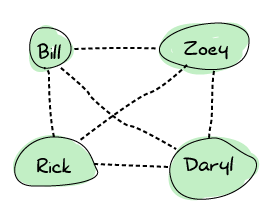
這表示任何倖存者都可以直接聯絡其他倖存者。這很有用,因為如果任何倖存者死亡,都不會有人被孤立。Erlang 節點的建立方式與此完全相同:每個人都連接到每個人。
不要喝太多 Kool-Aid
這種做事方式雖然在某些容錯原因上很好,但在您可以擴展的程度上卻存在相當嚴重的缺點。很難讓數百個節點成為您的 Erlang 叢集的一部分,僅僅是因為需要多少連線和多少聊天。事實上,您需要為您連接的每個節點提供一個連接埠。
如果您計畫使用 Erlang 進行這類繁重的設定,請繼續閱讀本章,我們將了解事情為何會這樣,以及是否有可能解決這個問題。
一旦節點連接在一起,它們仍然是完全獨立的:它們保留自己的進程登錄、自己的 ETS 表格(具有自己的表格名稱),並且它們載入的模組彼此獨立。崩潰的連接節點不會使其連接的節點崩潰。
連接的節點可以開始交換訊息。Erlang 的分散式模型經過設計,使本地進程可以聯絡遠端進程並向它們傳送常規訊息。如果沒有任何共享,且所有進程登錄都是唯一的,這怎麼可能?正如我們稍後在深入探討分散式細節時將看到的那樣,有一種方法可以存取特定節點上已註冊的進程。從此時起,可以傳送第一個訊息。
Erlang 訊息將以透明的方式自動為您序列化和反序列化。所有資料結構,包括 pid,都將在遠端和本機以相同的方式運作。這表示我們可以透過網路傳送 pid,然後與它們通信、傳送訊息等。甚至比這更好的是,如果您可以存取 pid,則可以在網路上設定連結和監控!
因此,如果 Erlang 為使一切都如此透明做了很多事情,為什麼我說它只給了我們一把彎刀、一個手電筒和一個鬍子?
分散式計算的謬論
就像彎刀只能殺死特定類型的怪物一樣,Erlang 的工具也只能處理某些類型的分散式計算。為了理解 Erlang 給我們的工具,首先了解分散式世界中存在哪些類型的狀況,以及 Erlang 為了提供容錯能力而做出的哪些假設,將會很有用。
在過去幾十年中,一些非常聰明的人花時間對分散式計算中出現錯誤的類型進行分類。他們提出了人們會犯的 8 個主要假設,這些假設最終會讓他們在以後付出代價,其中一些假設是 Erlang 設計者出於各種原因做出的。
網路是可靠的
分散式計算的第一個謬論是假設應用程式可以透過網路分散式。這說起來有點奇怪,但在很多時候,網路會因為令人討厭的原因而停機:電源故障、硬體損壞、有人絆倒電線、通往其他維度的渦流吞噬了關鍵組件、螃蟹頭入侵、銅線盜竊等等。
因此,您可能犯的最大錯誤之一是認為您可以聯絡遠端節點並與它們交談。透過增加更多硬體並獲得冗餘來處理這個問題是有點可能的,這樣如果某些硬體發生故障,仍然可以在其他地方存取應用程式。另一件要做的事情是準備承受訊息和請求的遺失,準備好讓事情變得沒有回應。當您依賴某些不再存在的第三方服務時,尤其如此,而您自己的軟體堆疊仍然運作良好。
Erlang 沒有任何特殊的措施來處理此問題,因為這通常是決策將是特定於應用程式的問題。畢竟,除了您之外,還有誰能知道特定組件有多重要?儘管如此,您並非完全孤單,因為分散式 Erlang 節點將能夠偵測到其他節點斷線(或變得沒有回應)。有一些特定函數可以用來監控節點,而且連線和監控器也會在斷線時觸發。
即使如此,Erlang 在這種情況下最好的優勢是其非同步通信模式。透過非同步傳送訊息並迫使開發人員在事情順利運作時回覆,Erlang 會推動所有訊息傳遞活動來直觀地處理故障。如果您正在交談的進程位於因某些網路故障而消失的節點上,我們會像處理任何本地崩潰一樣自然地處理它。這也是 Erlang 被稱為可以很好地擴展(效能和設計方面的擴展)的許多原因之一。
不要喝太多 Kool-Aid
跨節點連結和監控可能很危險。在發生網路故障時,所有遠端連結和監控器都會同時觸發。然後,這可能會產生數千個訊號和訊息傳送到各種進程,這會對系統造成沉重且意外的負載。
為不可靠的網路做好準備也意味著為突然故障做好準備,並確保您的系統不會因系統的一部分突然消失而癱瘓。
沒有延遲
看似良好的分散式系統的雙面刃之一是,它們通常最終會隱藏您正在進行的函數呼叫是遠端的事實。雖然您期望某些函數呼叫速度非常快,但在網路上執行它們根本不一樣。這就像是在披薩店內訂購披薩,和從另一個城市送披薩到您家之間的差異。雖然始終會有基本的等待時間,但在一種情況下,您的披薩可能會因為時間太長而變冷。
如果忘記網路通訊即使對於非常小的訊息也會使速度變慢,如果你總是期望非常快速的結果,這可能會是一個代價高昂的錯誤。Erlang 的模型在這方面對我們很好。由於我們使用隔離的進程、非同步訊息、逾時和始終考慮進程可能失敗的方式來設定本地應用程式,因此要實現分散式幾乎不需要做任何調整:逾時、連結、監控和非同步模式保持不變,並且仍然一樣可靠。我們從一開始就預期到這種問題,因此 Erlang 隱式地不假設沒有延遲。
然而,你可能會在設計中做出這種假設,並期望回覆比實際可能的速度更快。請留意這一點。
頻寬是無限的
儘管網路傳輸的速度越來越快,而且一般來說,隨著時間的推移,透過網路傳輸的每個位元組都變得更便宜,但假設發送大量的資料是簡單且容易的,這是有風險的。
一般來說,由於我們在本地建構應用程式的方式,我們在 Erlang 中不會有太多這方面的問題。記住,一個好技巧是發送有關正在發生的事情的訊息,而不是移動新的狀態(例如「玩家 X 找到物品 Y」,而不是一遍又一遍地發送玩家 X 的整個庫存)。
如果由於某些原因,你需要發送大型訊息,請務必格外小心。Erlang 分散式和多節點通訊的方式對大型訊息特別敏感。如果兩個節點連接在一起,它們所有的通訊都會傾向於發生在單個 TCP 連接上。由於我們通常希望在兩個進程之間保持訊息的順序(即使跨越網路),訊息將會透過連接依序發送。這意味著如果你有一個非常大的訊息,你可能會阻塞通道,導致所有其他訊息都無法傳送。
更糟糕的是,Erlang 會透過發送稱為心跳的東西來知道節點是否存活。心跳是在兩個節點之間定期發送的小訊息,基本上表示「我還活著,繼續保持!」它們就像我們在殭屍生存遊戲中倖存者之間定期傳送訊息一樣;「比爾,你在那裡嗎?」如果比爾沒有回覆,那麼你可能會認為他死了(或電池沒電了),他將不會收到你未來的通訊。無論如何,心跳是透過與一般訊息相同的通道發送的。
問題是,一個大型訊息可能會阻礙心跳訊息的傳送。太多的大型訊息長時間阻礙心跳,任何一個節點最終都會認為另一個節點沒有回應並斷開連接。這很糟糕。無論如何,避免這種情況發生的良好 Erlang 設計經驗法則是保持你的訊息小巧。這樣一切都會更好。
網路是安全的
當你使用分散式系統時,相信一切都是安全的、你可以信任你收到的訊息通常是非常危險的。這可能很簡單,例如有人意外地偽造訊息並將它們發送給你、有人攔截數據包並修改它們(或查看敏感資料),或者在最糟糕的情況下,有人能夠接管你的應用程式或它運行的系統。
就分散式 Erlang 而言,遺憾的是,這是一個假設。以下是 Erlang 的安全模型:
* 此處故意留白 *
是的。這是因為 Erlang 分散式最初是為了容錯和元件的冗餘而設計的。在該語言的早期,當它被用於電話交換機和其他電信應用程式時,Erlang 通常會部署在運行於最奇怪地方的硬體上 — 非常偏遠的地方,條件很奇怪(工程師有時必須將伺服器固定在牆上以避開潮濕的地面,或者在樹林中安裝客製化的加熱系統,以便硬體在最佳溫度下運行)。在這些情況下,你會有與主要硬體位於同一物理位置的備援硬體。這通常是分散式 Erlang 的運行場所,這也解釋了為什麼 Erlang 設計者假設有一個安全的網路可以運行。
遺憾的是,這意味著現代 Erlang 應用程式很少可以跨不同的資料中心叢集。事實上,不建議這樣做。大多數時候,你會希望你的系統基於許多較小的、隔離的 Erlang 節點叢集,這些節點通常位於單一位置。任何更複雜的事情都將需要留給開發人員:要麼切換到 SSL、實作他們自己的高階通訊層、透過安全通道進行隧道傳輸,或者重新實作節點之間的通訊協定。關於如何執行此操作的指引可以在 ERTS 使用者指南中找到,在 如何為 Erlang 分散式實作替代載體中。有關分散式協定的更多詳細資訊包含在 分散式協定中。即使在這些情況下,你也必須非常小心,因為如果有人獲得對其中一個分散式節點的存取權,他們就可以存取所有節點,並且可以執行他們可以執行的任何命令。
拓撲結構不會改變
當你第一次設計一個旨在多個伺服器上運行的分散式應用程式時,你可能會考慮到一個給定的伺服器數量,甚至可能是一個給定的主機名稱列表。也許你會根據特定的 IP 位址來設計東西。這可能是個錯誤。硬體會壞掉,營運人員會移動伺服器,新的機器會被加入,有些會被移除。你的網路拓撲結構會不斷變化。如果你的應用程式使用任何這些硬編碼的拓撲結構詳細資訊,那麼它將無法輕易地處理網路中的這些變化。
就 Erlang 而言,並沒有做出那樣的明確假設。然而,它很容易滲透到你的應用程式中。Erlang 節點都有一個名稱和一個主機名稱,它們可能會不斷變化。使用 Erlang 進程,你不僅要考慮進程的命名方式,還要考慮它現在在叢集中的位置。如果你硬編碼名稱和主機,你可能會在下次故障時遇到麻煩。不過,別太擔心,因為稍後我們將看到一些有趣的函式庫,讓我們可以忘記節點名稱和一般的拓撲結構,同時仍然能夠找到特定的進程。
只有一位管理員
無論如何,語言或函式庫的分散式層都無法為你準備好這一點。這種謬誤的想法是,你並不總是只有一個主要的操作員來操作你的軟體及其伺服器,儘管它可能被設計成好像只有一個操作員一樣。如果你決定在單個電腦上運行許多節點,那麼你可能永遠不必關心這個謬誤。然而,如果你要在不同的地點運行東西,或者第三方依賴你的程式碼,那麼你必須注意。
要注意的事情包括給其他人工具來診斷你的系統問題。當你可以手動操作虛擬機時,Erlang 在某種程度上很容易除錯 — 畢竟,你甚至可以在需要時動態重新載入程式碼。無法存取你的終端機並坐在節點前面的人將需要不同的工具來操作。
這種謬誤的另一個方面是,重新啟動伺服器、在資料中心之間移動實例或升級你的軟體堆疊的某些部分不一定只是由一個人或一個團隊控制。在非常大的軟體專案中,事實上很可能會有許多團隊,甚至許多不同的軟體公司,負責一個大型系統的不同部分。
如果你正在為你的軟體堆疊編寫協定,那麼能夠處理該協定的多個版本可能是必要的,這取決於你的使用者和合作夥伴升級其程式碼的速度快慢。該協定可能從一開始就包含有關其版本控制的資訊,或者能夠根據你的需求在交易中途更改。我相信你可以想到更多可能會出錯的例子。
傳輸成本為零
這是一個雙方面的假設。第一個與時間上的資料傳輸成本有關,第二個與金錢上的資料傳輸成本有關。
第一種情況假設序列化資料之類的事情幾乎是免費的、非常快速的,並且不會產生很大的作用。實際上,較大的資料結構序列化的時間比小的資料結構要長,然後需要在網路的另一端進行反序列化。無論你在網路上傳輸什麼,情況都是如此。小的訊息將有助於減少這種影響的明顯程度。
假設傳輸成本為零的第二個方面與傳輸資料的成本有關。在現代伺服器堆疊中,記憶體(無論是在 RAM 還是磁碟上)通常比頻寬成本便宜,頻寬是你必須持續支付的費用,除非你擁有事物運行的整個網路。在這種情況下,優化較少的請求和較小的訊息將會是有益的。
對於 Erlang 而言,由於其最初的使用案例,並沒有特別注意去做跨節點壓縮訊息之類的事情(儘管已經存在用於壓縮訊息的函數)。相反,原始設計者選擇讓人們在需要時實作他們自己的通訊層。因此,程式設計師有責任確保發送小的訊息,並採取其他措施來盡量減少傳輸資料的成本。
網路是同質的
最後這個假設是關於認為網路應用程式的所有元件都將說相同的語言,或者將使用相同的格式來一起運行。
對於我們的殭屍倖存者來說,這可能是關於不要假設所有倖存者在制定計劃時總是會說英語(或良好的英語),或者一個詞對不同的人來說會有不同的含義。

就程式設計而言,這通常是關於不要依賴封閉的標準,而是使用開放的標準,或者準備隨時從一種協定切換到另一種協定。當涉及到 Erlang 時,分散式協定是完全公開的,但所有 Erlang 節點都假設與它們通訊的人說相同的語言。試圖將自己整合到 Erlang 叢集的外國人必須學習說 Erlang 的協定,或者 Erlang 應用程式需要某種 XML、JSON 或其他格式的翻譯層。
如果它像鴨子一樣嘎嘎叫,走路也像鴨子,那麼它一定是鴨子。這就是為什麼我們有 C 節點之類的東西。C 節點(或 C 語言以外的其他語言中的節點)是基於這樣的想法建構的:任何語言和應用程式都可以實作 Erlang 的協定,然後假裝它是叢集中的 Erlang 節點。
用於資料交換的另一個解決方案是使用稱為 BERT 或 BERT-RPC 的東西。這是一種類似 XML 或 JSON 的交換格式,但指定為類似於 Erlang 外部術語格式 的東西。
簡而言之,你始終必須小心以下幾點:
- 你不應該假設網路是可靠的。Erlang 沒有任何特殊的措施來解決這個問題,除了檢測到你的某些地方出錯(儘管作為一個功能這還不錯)
- 網路可能會不時變慢。Erlang 提供了非同步機制並知道這一點,但你必須小心,以避免你的應用程式與此背道而馳並破壞它。
- 頻寬不是無限的。小而具描述性的訊息有助於尊重這一點。
- 網路不安全,而且 Erlang 預設沒有提供任何措施來解決這個問題。
- 網路的拓撲結構可能會改變。Erlang 沒有做出任何明確的假設,但你可能會對事物的位置和命名方式做出一些假設。
- 你(或你的組織)很少能完全控制事物的結構。你的系統的某些部分可能已過時、使用不同的版本,或在你預期之外的時間重新啟動或關閉。
- 傳輸資料是有成本的。同樣地,簡短的小訊息會有所幫助。
- 網路是異質的。並非所有事物都相同,資料交換應依賴有完善文件記錄的格式。
注意:分散式運算的謬誤是由 Arnon Rotem-Gal-Oz 在分散式運算謬誤解釋中提出的
死亡或活死人
了解分散式運算的謬誤應能部分解釋為什麼我們要在黑暗中與怪物搏鬥,但使用了更好的工具。仍然有很多問題和事情需要我們去做。其中許多是關於上述謬誤的設計決策,需要謹慎處理(小訊息、減少通訊等)。最麻煩的問題與節點死亡或網路不可靠有關。這個問題尤其棘手,因為沒有好的方法可以知道某個東西是死是活(在無法聯繫它的情況下)。
讓我們回到比爾、柔伊、瑞克和戴瑞這四位殭屍末日倖存者。他們都在一個安全屋相遇,在那裡休息了幾天,吃掉他們能找到的任何罐頭食品。過了一段時間後,他們不得不搬出去,分散到城鎮各地尋找更多資源。他們在小鎮邊緣的一個小營地設定了一個會合點。
在探險期間,他們透過對講機保持聯繫。他們會宣告他們發現的東西、清除的道路,也許他們還會找到新的倖存者。
現在假設在安全屋和會合點之間的某個時間點,瑞克試圖聯繫他的同伴。他成功地打電話給比爾和柔伊,與他們交談,但無法聯繫到戴瑞。比爾和柔伊也無法聯繫到他。問題是,完全沒有辦法知道戴瑞是被殭屍吞噬了,電池沒電了,睡著了,還是只是在地下。
團隊必須決定是否要繼續等待他,繼續呼叫一陣子,還是假設他死了並繼續前進。
分散式系統中的節點也存在同樣的困境。當節點變得沒有回應時,是因為硬體故障而消失了嗎?應用程式崩潰了嗎?網路壅塞了嗎?還是網路斷線了?在某些情況下,應用程式不再運行,你可以直接忽略該節點並繼續你正在做的事情。在其他情況下,應用程式仍在隔離的節點上運行;從該節點的角度來看,其他所有節點都死了。
Erlang 預設將無法存取的節點視為死節點,而將可存取的節點視為活節點。如果你想快速應對災難性故障,這種悲觀的方法是有道理的;它假設網路通常比系統中的硬體或軟體更不容易發生故障,這考慮到 Erlang 最初的使用方式是有道理的。樂觀的方法(假設節點仍然存活)可能會延遲與崩潰相關的措施,因為它假設網路比硬體或軟體更容易發生故障,因此會讓叢集等待更長的時間來重新整合斷線的節點。
這引出了一個問題。在悲觀的系統中,當我們認為已經死亡的節點突然又回來了,而且事實證明它從未死亡時,會發生什麼事?我們被一個活死人節點嚇了一跳,它有自己的生命,在各方面與叢集隔離:資料、連線等。可能會發生一些非常令人惱火的事情。
讓我們想像一下,你有一個系統,在兩個不同的資料中心有 2 個節點。在該系統中,使用者在他們的帳戶中有錢,每個節點都持有全部金額。然後,每次交易都會將資料同步到所有其他節點。當所有節點都正常時,使用者可以繼續花錢,直到他的帳戶空了,然後就不能再出售任何東西了。
軟體運作良好,但在某個時候,其中一個節點與另一個節點斷開連線。沒有辦法知道另一端是死是活。就我們所知,兩個節點可能仍然在接收來自公眾的請求,但彼此無法通訊。
可以採取兩種一般策略:停止所有交易,或者不停。選擇第一種策略的風險是你的產品變得不可用,而你正在賠錢。選擇第二種策略的風險是,一個帳戶中有 1000 美元的使用者現在有兩個可以接受 1000 美元交易的伺服器,總共 2000 美元!無論我們怎麼做,如果我們做得不對,我們都有賠錢的風險。
有沒有一種方法可以在網路分割期間保持應用程式的可用性,而無需在伺服器之間丟失資料,從而完全避免這個問題?

我的另一個帽子是一個定理
對前一個問題的快速回答是否。遺憾的是,在網路分割期間,沒有辦法同時保持應用程式的存活和正確。
這個想法被稱為CAP 定理(你可能也會對你不能犧牲分割容錯感興趣)。CAP 定理首先指出所有現有的分散式系統都具有三個核心屬性:C一致性、A可用性和P分割容錯。
一致性
在先前的範例中,一致性是指系統無論有 2 個或 1000 個可以回答查詢的節點,都能在給定的時間看到帳戶中完全相同的金額。這通常是透過添加交易(所有節點必須同意在進行更改之前將變更變更到資料庫)或其他同等機制來完成的。
根據定義,一致性的概念是所有操作看起來都像是單個不可分割的區塊完成的,即使跨越多個節點也是如此。這不是在時間方面,而是在沒有對同一資料進行兩個不同操作以修改它們,從而在這些操作期間提供系統報告的多個不同值方面。應該可以修改一塊資料,而不必擔心其他參與者在你執行操作的同時擅自修改它,從而破壞你的一天。
可用性
可用性的概念是,如果你向系統請求某些資料,你應該能夠得到回應。如果你沒有得到任何回應,那麼該系統對你來說就不可用。請注意,一個說「抱歉,我無法找出結果,因為我死了」的回應並不是真正的回應,而只是令人難過的藉口。這個回應中沒有比沒有回應更有用的資訊(儘管學術界在這個問題上有些分歧)。
注意: CAP 定理的一個重要考慮因素是,可用性僅對沒有死亡的節點才是一個問題。死節點無法發送回應,因為它首先無法接收查詢。這與節點無法發送回覆,因為它所依賴的東西不再存在的情況不同!如果節點無法接受請求、變更資料或返回錯誤的結果,那麼從正確性的角度來看,它在技術上不會對系統的平衡構成威脅。叢集的其餘部分只需要處理更多的負載,直到它恢復正常並可以同步。
分割容錯
這是 CAP 定理中棘手的部分。分割容錯通常是指即使系統的某些部分無法再相互通訊,系統仍然可以繼續運作(並包含有用的資訊)。分割容錯的重點在於系統可以在元件之間可能遺失訊息的情況下運作。這個定義有點抽象且開放,我們將了解原因。
CAP 定理基本上指定在任何分散式系統中,你只能擁有 CAP 中的兩個:CA、CP 或 AP。沒有辦法同時擁有所有三個。這既是壞消息也是好消息。壞消息是即使網路發生故障,也不可能讓一切都始終順利。好消息是這是一個定理。如果客戶要求你提供所有三個,你將有機會告訴他們這在字面上是不可能做到的,而且除了向他們解釋 CAP 定理是什麼之外,不需要花費太多時間。
在三種可能性中,我們通常可以忽略的一種是 CA(一致性 + 可用性)的概念。這樣做的原因是,只有在你敢說網路永遠不會發生故障,或者如果發生故障,它會作為一個原子單元(如果一件事發生故障,所有事情都會同時發生)時,你才真正需要它。
在有人發明永遠不會發生故障的網路和硬體,或者有辦法在系統的一部分發生故障時讓所有部分同時發生故障之前,故障將會是一個選項。CAP 定理只剩下兩種組合:AP 或 CP。被網路分割撕裂的系統可以保持可用性或一致性,但不能兩者兼得。
注意:有些系統會選擇不具有「A」或「C」。在某些高效能的情況下,諸如輸送量(你總共可以回答多少個查詢)或延遲(你可以多快回答查詢)之類的條件會以某種方式扭曲事情,以至於 CAP 定理不是關於 2 個屬性(CA、CP 或 AP),而是關於 2 個或更少的屬性。
對於我們的倖存者團體來說,時間流逝,他們與一群不死生物搏鬥了很長時間。子彈刺穿了腦袋,棒球棍打碎了頭骨,被咬的人被拋在了後面。比爾、柔伊、瑞克和戴瑞的電池最終耗盡,他們無法通訊。幸運的是,他們都找到了兩個倖存者聚落,其中居住著迷戀於殭屍生存的電腦科學家和工程師。聚落倖存者習慣於分散式程式設計的概念,並習慣於使用自製協定以光信號和鏡子進行通訊。
比爾和柔伊發現了「電鋸」聚落,而瑞克和戴瑞則找到了「十字弓」營地。鑑於我們的倖存者是他們各自聚落的最新成員,他們經常被指派到野外去,為每個聚落尋找食物並殺死太靠近邊界的殭屍,而其他人則在辯論 vim 與 emacs 的優劣,這是殭屍末日完全結束後唯一無法消亡的戰爭。
在那裡的第一百天,我們的四位倖存者被派到營地中途會面,為每個聚落交換物資。
在離開之前,電鋸和十字弓聚落決定了一個會合點。如果目的地或會面時間在任何時間點發生變化,瑞克和戴瑞可以向十字弓聚落發送訊息,而柔伊和比爾可以向電鋸聚落發送訊息。然後,每個聚落都會將資訊傳達給另一個聚落,另一個聚落會將變更轉發給其他倖存者。
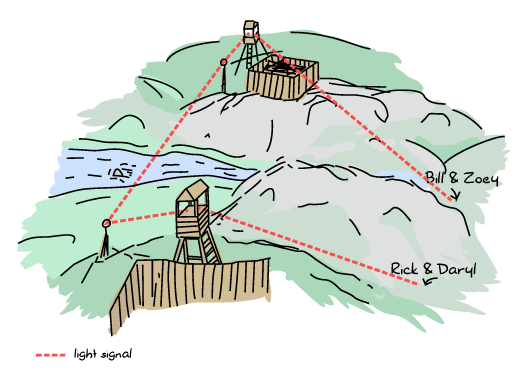
所以知道這一點後,所有四位倖存者在星期天早上很早就出發了,徒步長途跋涉,原定於星期五黎明前會面。一切都很順利(除了偶爾與已經活了很久的死人發生衝突)。
不幸的是,在星期三,大雨和殭屍活動加劇導致比爾和柔伊分開、迷路和延遲。新情況看起來有點像這樣
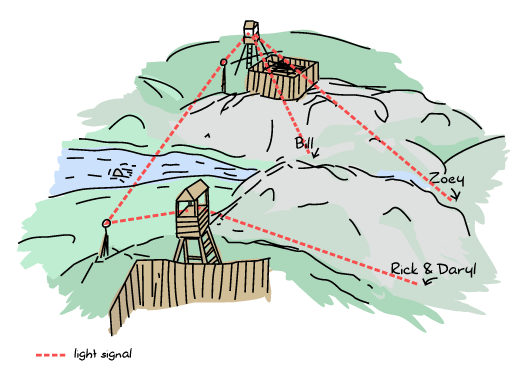
更糟的是,雨後,兩個聚落之間通常晴朗的天空變得霧濛濛的,電鋸電腦科學家無法與十字弓的人員通訊。
比爾和柔伊將他們的問題傳達給他們的聚落,並要求設定新的會面時間。如果沒有霧,這本來沒問題,但現在我們有了相當於網路分割的情況。
如果兩個陣營都採用「一致性 + 分割容錯」的方法,他們只會阻止柔伊和比爾設定新的會議時間。你看,CP 方法通常都是為了阻止數據修改以保持一致性,而且所有倖存者仍然可以不時向各自的陣營詢問日期。他們只會被拒絕更改的權利。這樣做可以確保沒有任何倖存者能夠搞砸預定的會議時間——任何與外界失去聯繫的倖存者仍然可以獨立地準時到達那裡。
如果兩個陣營改為選擇「可用性 + 分割容錯」,那麼倖存者就可以被允許更改會議日期。分割的每一方都會有自己的會議數據版本。因此,如果比爾要求將會議改到星期五晚上,則總體狀態會變成這樣:
Chainsaw: Friday night Crossbow: Friday before dawn
只要分割持續,比爾和柔伊只會從電鋸那裡獲取資訊,而瑞克和戴瑞只會從十字弓那裡獲取資訊。這讓部分倖存者在需要時可以重新組織自己。
這裡有趣的問題是,當分割解決(迷霧散去)時,如何處理不同的數據版本。CP 方法對此非常直接:數據沒有改變,沒有什麼需要做的。AP 方法則有更大的彈性和更多問題需要解決。通常會採用不同的策略
- 後寫勝出 是一種衝突解決方法,無論最後的更新是什麼,都將保留該更新。這個方法可能很棘手,因為在分散式環境中,時間戳記可能會偏移或事情可能在完全相同的時間發生。
- 可以隨機選擇一個勝出者。
- 更複雜的方法有助於減少衝突,包括基於時間的方法,例如後寫勝出,但使用相對時鐘。相對時鐘不使用絕對時間值,而是每次有人修改文件時都會遞增的值。如果您想了解更多相關資訊,請閱讀 Lamport 時鐘 或 向量時鐘。
- 可以將選擇如何處理衝突的責任推回給應用程式(或者在我們的例子中,推給倖存者)。接收端只需要選擇哪個衝突的條目是正確的。這有點像您在使用 SVN、Mercurial、Git 等原始碼控制時遇到合併衝突的情況。
哪一個比較好?我描述事情的方式有點讓我們相信,我們可以選擇完全是 AP 或完全是 CP,就像一個開/關開關。在現實世界中,我們可以有多種系統,例如仲裁系統,在這種系統中,我們將這個「是/否」問題變成一個我們可以轉動的刻度盤,以選擇我們想要多少一致性。
仲裁系統的工作原理遵循幾個非常簡單的規則。系統中有 N 個節點,並且需要 M 個節點同意修改數據才能使其成為可能。一致性要求相對較低的系統可能只需要 15% 的節點可用即可進行變更。這表示在分割的情況下,即使是網路的一小部分仍然能夠修改數據。較高的一致性等級(可能設定為 75% 的節點)表示需要系統中較大的部分才能進行變更。在這種情況下,如果幾個節點被隔離,它們將無權更改數據。但是,仍然互連的系統主要部分可以正常工作。
透過將所需節點的 M 值更改為 N(節點總數),您可以擁有完全一致的系統。透過將 M 設定為值 1,您將擁有完全 AP 的系統,而沒有任何一致性保證。
此外,您可以針對每個查詢調整這些值:與不太重要的事情(有人剛登錄!)相關的查詢可以有較低的一致性要求,而與庫存和金錢相關的事情可能需要更多的一致性。將此與每個案例的不同衝突解決方法混合使用,您可以獲得驚人的靈活系統。
結合所有可用的不同衝突解決方案,分散式系統可以有許多選擇,但它們的實作仍然非常複雜。我們不會詳細使用它們,但我認為了解有哪些可用選項以了解不同的可用選項非常重要。
現在,我們可以堅持使用 Erlang 的分散式計算基礎知識。
設定 Erlang 叢集
除了處理分散式計算謬誤的整個部分之外,分散式 Erlang 最困難的部分是首先設法正確設定一切。跨不同主機連接節點是一種特殊的痛苦。為了避免這種情況,我們通常會嘗試在單台電腦上使用多個節點,這往往會讓事情變得更容易。
如前所述,Erlang 會為每個節點命名,以便能夠定位和聯絡它們。名稱的格式為 Name@Host,其中主機基於可用的 DNS 條目,無論是透過網路還是在您電腦的主機檔案中(OSX、Linux 和其他類 Unix 系統上的 /etc/hosts,大多數 Windows 安裝的 C:\Windows\system32\drivers\etc\hosts)。所有名稱都需要是唯一的,以避免衝突——如果您嘗試使用與同一主機名稱上另一個節點相同的名稱啟動節點,您會收到非常糟糕的崩潰訊息。
在啟動這些 Shell 來引發崩潰之前,我們必須了解一些關於名稱的知識。名稱有兩種型別:短名稱和長名稱。長名稱基於完整網域名稱 (aaa.bbb.ccc),而且許多 DNS 解析器會將包含句點 (.) 的網域名稱視為完整網域名稱。短名稱將基於不帶句點的主機名稱,並且會透過您的主機檔案或任何可能的 DNS 條目進行解析。因此,通常使用短名稱比長名稱更容易在一台電腦上設定一堆 Erlang 節點。最後一件事:由於名稱必須是唯一的,因此具有短名稱的節點無法與具有長名稱的節點通訊,反之亦然。
要選擇長名稱或短名稱,您可以使用兩個不同的選項啟動 Erlang VM:erl -sname short_name@domain 或 erl -name long_name@some.domain。請注意,您也可以僅使用名稱啟動節點:erl -sname short_name 或 erl -name long_name。Erlang 將根據您的作業系統配置自動指定主機名稱。最後,您也可以選擇使用諸如 erl -name name@127.0.0.1 之類的名稱啟動節點以指定直接 IP。
注意:Windows 使用者仍然應該使用 werl 而不是 erl。但是,為了啟動分散式節點並為它們命名,應該從命令列啟動節點,而不是點擊某些捷徑或可執行檔。
讓我們啟動兩個節點
erl -sname ketchup ... (ketchup@ferdmbp)1>
erl -sname fries ... (fries@ferdmbp)1>
要將薯條與番茄醬連接起來(並建立一個美味的叢集),請轉到第一個 Shell 並輸入以下函式
(ketchup@ferdmbp)1> net_kernel:connect_node(fries@ferdmbp). true
net_kernel:connect_node(NodeName) 函式會設定與另一個 Erlang 節點的連線(一些教學使用 net_adm:ping(Node),但我認為 net_kernel:connect_node/1 聽起來更嚴肅並且讓我更有說服力!)如果您看到函式呼叫的結果為 true,那麼恭喜,您現在處於分散式 Erlang 模式。如果您看到 false,那麼您將會為了讓您的網路正常運作而付出巨大的努力。若要快速修復,請編輯您的主機檔案以接受您想要的任何主機。再試一次,看看它是否有效。
您可以透過呼叫 BIF node() 來查看您自己的節點名稱,並透過呼叫 BIF nodes() 來查看您要連線的對象
(ketchup@ferdmbp)2> node(). ketchup@ferdmbp (ketchup@ferdmbp)3> nodes(). [fries@ferdmbp]
為了讓節點一起通訊,我們將嘗試一個非常簡單的技巧。將每個 Shell 的程序在本機註冊為 shell
(ketchup@ferdmbp)4> register(shell, self()). true
(fries@ferdmbp)1> register(shell, self()). true
然後,您將能夠按名稱呼叫該程序。方法是將訊息傳送給 {Name, Node}。讓我們在兩個 Shell 上試試這個
(ketchup@ferdmbp)5> {shell, fries@ferdmbp} ! {hello, from, self()}.
{hello,from,<0.52.0>}
(fries@ferdmbp)2> receive {hello, from, OtherShell} -> OtherShell ! <<"hey there!">> end.
<<"hey there!">>
因此,該訊息顯然已收到,並且我們向另一個 Shell 發送了一些訊息,該 Shell 收到了該訊息
(ketchup@ferdmbp)6> flush(). Shell got <<"hey there!">> ok
如您所見,我們可以透明地發送元組、原子、PID 和二進制檔案,而不會有問題。任何其他 Erlang 數據結構也都可以。就是這樣。您知道如何使用分散式 Erlang 了!還有另一個可能有用的 BIF:erlang:monitor_node(NodeName, Bool)。如果節點當機,此函式將讓呼叫它並將 Bool 的值設為 true 的程序接收到格式為 {nodedown, NodeName} 的訊息。
除非您正在編寫一個依賴於檢查其他節點生命週期的特殊程式庫,否則您很少需要使用 erlang:monitor_node/2。原因是像 link/1 和 monitor/2 這樣的函式仍然可以跨節點工作。
如果您從 fries 節點設定以下內容
(fries@ferdmbp)3> process_flag(trap_exit, true). false (fries@ferdmbp)4> link(OtherShell). true (fries@ferdmbp)5> erlang:monitor(process, OtherShell). #Ref<0.0.0.132>
然後關閉 ketchup 節點,fries 的 Shell 程序應該會收到 'EXIT' 和監控訊息
(fries@ferdmbp)6> flush().
Shell got {'DOWN',#Ref<0.0.0.132>,process,<6349.52.0>,noconnection}
Shell got {'EXIT',<6349.52.0>,noconnection}
ok
這就是您會看到的東西。但是,等等。為什麼 PID 看起來像那樣?我看到的是真的嗎?
(fries@ferdmbp)7> OtherShell. <6349.52.0>
什麼?這不應該是 <0.52.0> 嗎?不是。你看,顯示 PID 的方式只是某種視覺表示,表示程序識別碼的真實樣子。第一個數字表示節點(其中 0 表示程序來自目前的節點),第二個數字是一個計數器,第三個數字是第二個計數器,用於在您建立了太多程序以至於第一個計數器不夠用時。PID 的真正底層表示更像這樣
(fries@ferdmbp)8> term_to_binary(OtherShell). <<131,103,100,0,15,107,101,116,99,104,117,112,64,102,101, 114,100,109,98,112,0,0,0,52,0,0,0,0,3>>
二進制序列 <<107,101,116,99,104,117,112,64,102,101,114,100,109,98,112>> 實際上是 <<"ketchup@ferdmbp">> 的 latin-1(或 ASCII)表示,即程序所在的節點的名稱。然後我們有兩個計數器,<<0,0,0,52>> 和 <<0,0,0,0>>。最後一個值 (3) 是一些權杖值,用於區分 PID 是來自舊節點、已關閉節點等。這就是為什麼 PID 可以透明地在任何地方使用。
注意: 您可能還想嘗試使用 BIF erlang:disconnect_node(Node) 來移除節點,而不是關閉節點以中斷連線,而無需關閉它。
注意: 如果您不確定 PID 來自哪個節點,則無需將其轉換為二進制來讀取節點名稱。只需呼叫 node(Pid),它將返回執行該節點的字串。
其他有趣且可用的 BIF 有 spawn/2、spawn/4、spawn_link/2 和 spawn_link/4。它們的工作方式與其他 spawn BIF 完全相同,只是這些 BIF 允許您在遠端節點上產生函式。從番茄醬節點嘗試這個
(ketchup@ferdmbp)6> spawn(fries@ferdmbp, fun() -> io:format("I'm on ~p~n", [node()]) end).
I'm on fries@ferdmbp
<6448.50.0>
這本質上是一個遠端程序呼叫:我們可以選擇在其他節點上執行任意程式碼,而無需給自己帶來更多麻煩!有趣的是,該函式在另一個節點上執行,但我們會在本地接收輸出。沒錯,即使輸出也可以透明地跨網路重新導向。這樣做的原因是基於群組領導者的概念。無論是本地還是非本地,群組領導者的繼承方式都相同。
這些是您在 Erlang 中能夠編寫分散式程式碼所需的所有工具。您剛剛收到了您的開山刀、手電筒和鬍子。您現在的程度,若沒有這樣的分散式層,其他語言需要很長時間才能達到。現在是時候殺死怪物了。或者,也許首先,我們必須了解餅乾怪獸。
Cookie

如果您回想起本章的開頭,我曾經提到過所有 Erlang 節點都設定為網格的想法。如果有人連線到一個節點,它就會連線到所有其他節點。有時候您想要做的是在同一硬體上執行不同的 Erlang 節點叢集。在這些情況下,您不希望意外地將兩個 Erlang 節點叢集連接在一起。
有鑑於此,Erlang 的設計者加入了一個稱為 cookie 的小權杖值。雖然官方 Erlang 文件等將 cookie 歸類在安全性主題下,但它們實際上根本不是安全性的一部分。如果說它是,那一定是在開玩笑,因為沒有人會認真地認為 cookie 是安全的東西。為什麼?很簡單,因為 cookie 是一個在節點之間共享的小型唯一值,以允許它們彼此連接。它們更接近使用者名稱的概念,而不是密碼,而且我確信沒有人會認為只有使用者名稱(而沒有其他東西)是一種安全功能。將 cookie 作為區分節點叢集的機制,比將其作為身份驗證機制更有意義。
要將 cookie 給予一個節點,只需在啟動時,於命令列中加入 -setcookie Cookie 參數。讓我們用兩個新的節點再試一次
$ erl -sname salad -setcookie 'myvoiceismypassword' ... (salad@ferdmbp)1>
$ erl -sname mustard -setcookie 'opensesame' ... (mustard@ferdmbp)1>
現在這兩個節點有不同的 cookie,它們應該無法互相通訊
(salad@ferdmbp)1> net_kernel:connect_node(mustard@ferdmbp). false
這個請求被拒絕了。沒有太多解釋。但是,如果我們看看 mustard 節點
=ERROR REPORT==== 10-Dec-2011::13:39:27 === ** Connection attempt from disallowed node salad@ferdmbp **
很好。現在如果我們真的想讓 salad 和 mustard 在一起呢?有一個名為 erlang:set_cookie/2 的 BIF 可以做我們需要的事情。如果您呼叫 erlang:set_cookie(OtherNode, Cookie),則只會在連線到另一個節點時使用該 cookie。如果您改為使用 erlang:set_cookie(node(), Cookie),您將會變更節點目前的所有未來連線 cookie。要查看變更,請使用 erlang:get_cookie()
(salad@ferdmbp)2> erlang:get_cookie(). myvoiceismypassword (salad@ferdmbp)3> erlang:set_cookie(mustard@ferdmbp, opensesame). true (salad@ferdmbp)4> erlang:get_cookie(). myvoiceismypassword (salad@ferdmbp)5> net_kernel:connect_node(mustard@ferdmbp). true (salad@ferdmbp)6> erlang:set_cookie(node(), now_it_changes). true (salad@ferdmbp)7> erlang:get_cookie(). now_it_changes
太棒了。還有最後一個 cookie 機制需要瞭解。如果您嘗試過本章前面的範例,請查看您的主目錄。其中應該有一個名為 .erlang.cookie 的檔案。如果您讀取它,您會看到一個隨機字串,看起來有點像 PMIYERCHJZNZGSRJPVRK。每當您啟動一個沒有特定命令給予 cookie 的分散式節點時,Erlang 都會建立一個 cookie 並將其放入該檔案中。然後,每次您再次啟動沒有指定 cookie 的節點時,虛擬機器都會查看您的主目錄,並使用該檔案中的內容。
遠端 Shell
我們在 Erlang 中學到的第一件事是如何使用 ^G (CTRL + G) 中斷正在執行的程式碼。在那裡,我們看到一個分散式 shell 的選單
(salad@ferdmbp)1> User switch command --> h c [nn] - connect to job i [nn] - interrupt job k [nn] - kill job j - list all jobs s [shell] - start local shell r [node [shell]] - start remote shell q - quit erlang ? | h - this message
我們正在尋找的是 r [node [shell]] 選項。我們可以通過以下方式在 mustard 節點上啟動一個工作
--> r mustard@ferdmbp
--> j
1 {shell,start,[init]}
2* {mustard@ferdmbp,shell,start,[]}
--> c
Eshell V5.8.4 (abort with ^G)
(mustard@ferdmbp)1> node().
mustard@ferdmbp
您現在可以使用遠端 shell,就像使用本機 shell 一樣。與舊版本的 Erlang 有一些差異,例如自動完成等功能不再起作用。當您需要在使用 -noshell 選項執行的節點上變更某些內容時,這種方法仍然非常有用。如果 -noshell 節點有名稱,則您可以連線到它來執行與管理相關的操作,例如重新載入模組、偵錯某些程式碼等等。
再次使用 ^G,您可以返回原始節點。但是,當您停止您的會話時請小心。如果您呼叫 q() 或 init:stop(),您將終止遠端節點!

隱藏節點
Erlang 節點可以透過呼叫 net_kernel:connect_node/1 連接,但是您必須知道,節點之間的任何互動幾乎都會讓它們建立連線。呼叫 spawn/2 或傳送訊息到外部 Pid 都會自動建立連線。
如果您有一個還不錯的叢集,並且只想連線到單一節點來變更一些內容,這可能會相當惱人。您不會希望您的管理節點突然整合到叢集中,並讓其他節點認為它們有一個新的同事可以傳送任務。為此,您可以使用很少使用的 erlang:send(Dest, Message, [noconnect]) 函式,它會傳送訊息而不建立連線,但是這種方法很容易出錯。
相反地,您想要做的是使用 -hidden 標誌設定一個節點。假設您仍然在執行 mustard 和 salad 節點。我們將啟動第三個節點 olives,它只會連線到 mustard(請確保 cookie 相同!)
$ erl -sname olives -hidden ... (olives@ferdmbp)1> net_kernel:connect_node(mustard@ferdmbp). true (olives@ferdmbp)2> nodes(). [] (olives@ferdmbp)3> nodes(hidden). [mustard@ferdmbp]
啊哈!該節點沒有連線到 salad,而且乍看之下,它也沒有連線到 mustard。但是,呼叫 node(hidden) 顯示我們確實有連線!讓我們看看 mustard 節點看到了什麼
(mustard@ferdmbp)1> nodes(). [salad@ferdmbp] (mustard@ferdmbp)2> nodes(hidden). [olives@ferdmbp] (mustard@ferdmbp)3> nodes(connected). [salad@ferdmbp,olives@ferdmbp]
類似的視圖,但現在我們加入 nodes(connected) BIF,它會顯示所有連線,無論其類型為何。除非特別指示連線,否則 salad 節點永遠不會看到任何與 olives 的連線。nodes/1 最後一個有趣的用法是使用 nodes(known),它會顯示目前節點曾經連線過的所有節點。
有了遠端 shell、cookie 和隱藏節點,管理分散式 Erlang 系統變得更加簡單。
牆壁是用火做的,護目鏡沒有任何作用
如果您發現自己想要透過防火牆使用分散式 Erlang(且不想使用通道),您可能會想要開啟一些連接埠以進行 Erlang 通訊。如果您想要這樣做,您會想要開啟連接埠 4369,這是 EPMD 的預設連接埠。使用這個連接埠是個好主意,因為它已由 Ericsson 正式註冊用於 EPMD。這表示您使用的任何符合標準的作業系統都將擁有該空閒的連接埠,隨時可用於 EPMD。
然後,您會想要開啟一系列連接埠以進行節點之間的連線。問題在於,Erlang 只是將隨機連接埠號碼指派給節點之間的連線。但是,有兩個隱藏的應用程式變數可讓您指定可指派連接埠的範圍。這兩個值分別是來自 kernel 應用程式的 inet_dist_listen_min 和 inet_dist_listen_max。
例如,您可以像這樣啟動 Erlang:erl -name left_4_distribudead -kernel inet_dist_listen_min 9100 -kernel inet_dist_listen_max 9115,以設定一個範圍為 16 個連接埠,用於 Erlang 節點。或者,您也可以使用類似這樣的設定檔 ports.config
[{kernel,[
{inet_dist_listen_min, 9100},
{inet_dist_listen_max, 9115}
]}].
然後像這樣啟動 Erlang 節點:erl -name the_army_of_darknodes -config ports。變數將以相同方式設定。
來自遠方的呼叫
除了我們已看到的 BIF 和概念之外,還有一些模組可用來協助開發人員處理分散式。第一個是 net_kernel,我們使用它來連線節點,並且如先前所述,可以用來中斷連線。
它還有一些其他的功能,例如能夠將非分散式節點轉換為分散式節點
erl
...
1> net_kernel:start([romero, shortnames]).
{ok,<0.43.0>}
(romero@ferdmbp)2>
您可以在其中使用 shortnames 或 longnames 來定義您是否想要具有與 -sname 或 -name 等效的名稱。此外,如果您知道某個節點將傳送大型訊息,因此可能需要節點之間較長的心跳時間,則可以將第三個引數傳遞到清單。這會產生 net_kernel:start([Name, Type, HeartbeatInMilliseconds])。預設情況下,心跳延遲設定為 15 秒,即 15,000 毫秒。在 4 次心跳失敗後,遠端節點會被視為已死。心跳延遲乘以 4 稱為滴答時間。
此模組的其他函數包括 net_kernel:set_net_ticktime(S),可讓您變更節點的滴答時間,以避免斷線(其中 S 這次以秒為單位,而且由於它是滴答時間,因此必須是心跳延遲的 4 倍!),以及 net_kernel:stop(),以停止分散式並返回成為一般節點
(romero@ferdmbp)2> net_kernel:set_net_ticktime(5). change_initiated (romero@ferdmbp)3> net_kernel:stop(). ok 4>
下一個有用的分散式模組是 global。global 模組是一個新的替代程序註冊表。它會自動將其資料散佈到所有連線的節點,在那裡複寫資料,處理節點失敗,並在節點重新上線時支援不同的衝突解決策略。
您可以使用 global:register_name(Name, Pid) 來註冊名稱,使用 global:unregister_name(Name) 來取消註冊。如果您想在沒有任何名稱指向的情況下執行名稱傳輸,您可以呼叫 global:re_register_name(Name, Pid)。您可以使用 global:whereis_name(Name) 來尋找程序的 ID,並使用 global:send(Name, Message) 將訊息傳送到其中。您所需要的一切都在這裡。特別棒的是,您用來註冊程序的名稱可以是任何 term。
當兩個節點連線且它們都有兩個不同的程序共用相同名稱時,就會發生命名衝突。在這種情況下,global 會預設隨機終止其中一個程序。有一些方法可以覆寫該行為。每當您註冊或重新註冊名稱時,請將第三個引數傳遞給該函式
5> Resolve = fun(_Name,Pid1,Pid2) ->
5> case process_info(Pid1, message_queue_len) > process_info(Pid2, message_queue_len) of
5> true -> Pid1;
5> false -> Pid2
5> end
5> end.
#Fun<erl_eval.18.59269574>
6> global:register_name({zombie, 12}, self(), Resolve).
yes
Resolve 函式會選取其信箱中訊息最多的程序作為要保留的程序(這是該函式返回其 pid 的程序)。您也可以聯絡這兩個程序,並詢問誰的訂閱者最多,或只保留第一個回覆的程序等等。如果 Resolve 函式當機或返回的不是 pid,則會取消註冊程序名稱。為了您的方便,global 模組已經為您定義了三個函式
fun global:random_exit_name/3將隨機終止一個程序。這是預設選項。fun global:random_notify_name/3將隨機選擇兩個程序中的一個作為倖存者,並將{global_name_conflict, Name}傳送給失敗的程序。fun global:notify_all_name/3它會取消註冊這兩個 pid,並將訊息{global_name_conflict, Name, OtherPid}傳送給這兩個程序,並讓它們自行解決問題,以便它們再次重新註冊。

global 模組有一個缺點,那就是它通常被認為偵測名稱衝突和節點關閉的速度相當慢。否則,它是一個很好的模組,甚至受到行為的支援。只需將所有使用本機名稱 ({local, Name}) 的 gen_Something:start_link(...) 呼叫變更為改用 {global, Name},然後將所有呼叫和轉換(及其等效項)變更為使用 {global, Name} 而不是僅使用 Name,這樣事情就會分散式。
清單上的下一個模組是 rpc,代表 遠端程序呼叫。它包含一些函式,可讓您在遠端節點上執行命令,以及一些有助於平行操作的函式。為了測試這些函式,我們先啟動兩個不同的節點並將它們連接在一起。這次我不會顯示這些步驟,因為我假設您現在了解這項操作的運作方式。這兩個節點將會是 cthulu 和 lovecraft。
最基本的 rpc 操作是 rpc:call/4-5。它可讓您在遠端節點上執行給定的操作,並在本機取得結果
(cthulu@ferdmbp)1> rpc:call(lovecraft@ferdmbp, lists, sort, [[a,e,f,t,h,s,a]]).
[a,a,e,f,h,s,t]
(cthulu@ferdmbp)2> rpc:call(lovecraft@ferdmbp, timer, sleep, [10000], 500).
{badrpc,timeout}
如這個 Cthulu 節點的呼叫所示,具有四個引數的函式採用 rpc:call(Node, Module, Function, Args) 的形式。加入第五個引數會提供逾時。rpc 呼叫將會返回它執行的函式所返回的任何內容,或者在失敗的情況下返回 {badrpc, Reason}。
如果您之前研究過一些分散式或平行運算概念,您可能聽過 promise。Promise 有點像遠端程序呼叫,只是它們是異步的。rpc 模組可讓我們擁有這個功能
(cthulu@ferdmbp)3> Key = rpc:async_call(lovecraft@ferdmbp, erlang, node, []). <0.45.0> (cthulu@ferdmbp)4> rpc:yield(Key). lovecraft@ferdmbp
透過將函式 rpc:async_call/4 的結果與函式 rpc:yield(Res) 結合,我們可以擁有異步遠端程序呼叫,並稍後擷取結果。當您知道您將進行的 RPC 需要一段時間才能返回時,這個功能特別有用。在這種情況下,您將它傳送出去,同時忙於進行其他操作(其他呼叫、從資料庫擷取記錄、喝茶),然後在完全沒有其他事情要做時等待結果。當然,如果您需要,您可以在自己的節點上進行此類呼叫
(cthulu@ferdmbp)5> MaxTime = rpc:async_call(node(), timer, sleep, [30000]). <0.48.0> (cthulu@ferdmbp)6> lists:sort([a,c,b]). [a,b,c] (cthulu@ferdmbp)7> rpc:yield(MaxTime). ... [long wait] ... ok
如果萬一您想要將 yield/1 函式與逾時值一起使用,請改用 rpc:nb_yield(Key, Timeout)。若要輪詢結果,請使用 rpc:nb_yield(Key)(相當於 rpc:nb_yield(Key,0))
(cthulu@ferdmbp)8> Key2 = rpc:async_call(node(), timer, sleep, [30000]).
<0.52.0>
(cthulu@ferdmbp)9> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)10> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)11> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)12> rpc:nb_yield(Key2, 1000).
timeout
(cthulu@ferdmbp)13> rpc:nb_yield(Key2, 100000).
... [long wait] ...
{value,ok}
如果您不在乎結果,那麼您可以使用 rpc:cast(Node, Mod, Fun, Args) 將命令傳送到另一個節點,然後忘記它。
未來掌握在您手中!但是等等,如果我們想要一次呼叫多個節點該怎麼辦?讓我們在我們的小型叢集中加入三個節點:minion1、minion2 和 minion3。那些是克蘇魯的僕從。當我們想問他們問題時,我們必須發送 3 個不同的呼叫,當我們想下達命令時,我們必須執行 3 次 cast。這非常糟糕,而且無法隨著龐大軍隊的規模擴展。
訣竅是針對呼叫和 cast 分別使用兩個 RPC 函數:rpc:multicall(Nodes, Mod, Fun, Args)(具有可選的 Timeout 參數)和 rpc:eval_everywhere(Nodes, Mod, Fun, Args)
(cthulu@ferdmbp)14> nodes().
[lovecraft@ferdmbp, minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp]
(cthulu@ferdmbp)15> rpc:multicall(nodes(), erlang, is_alive, []).
{[true,true,true,true],[]}
這明確地告訴我們,所有四個節點都處於活動狀態(而且沒有人無法回應)。元組的左側是處於活動狀態,右側則不是。是的,erlang:is_alive() 僅返回它運行的節點是否處於活動狀態,這看起來可能有點奇怪。再次提醒,在分散式環境中,alive 的意思是「可以連線到」,而不是「正在運行」。然後,假設克蘇魯不太欣賞他的僕從,並決定殺死他們,或者更確切地說,說服他們自殺。這是一項命令,因此它是 cast。因此,我們在僕從節點上使用 eval_everywhere/4 呼叫 init:stop()
(cthulu@ferdmbp)16> rpc:eval_everywhere([minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp], init, stop, []).
abcast
(cthulu@ferdmbp)17> rpc:multicall([lovecraft@ferdmbp, minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp], erlang, is_alive, []).
{[true],[minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp]}
當我們再次詢問誰處於活動狀態時,只剩下一個節點,即 Lovecraft 節點。僕從們是聽話的生物。其中還有一些更有趣的 RPC 函數,但這裡涵蓋了核心用途。如果您想了解更多信息,我建議您仔細閱讀該模組的文件。
埋葬分佈之書
好了,這就是關於分散式 Erlang 的大部分基本知識。有很多事情需要考慮,有很多屬性需要牢記。每當您必須開發分散式應用程式時,請問自己您可能會遇到哪些分散式運算謬誤(如果有的話)。如果客戶要求您建構一個在保持一致性和可用性的同時處理網路分割的系統,您知道您需要冷靜地解釋 CAP 理論或逃跑(或許可以從窗戶跳出去,以達到最大的效果)。
一般來說,數千個獨立節點可以在沒有彼此通信或依賴的情況下完成工作的應用程式將提供最佳的可擴展性。建立的節點間依賴關係越多,擴展就越困難,無論您有哪種類型的分佈層。這就像殭屍(不,真的!)。殭屍之所以可怕,是因為它們數量眾多,而且作為一個群體,它們難以置信地難以殺死。儘管個別殭屍可能非常緩慢且遠不具威脅性,但即使失去許多殭屍成員,一群殭屍也能造成相當大的破壞。人類倖存者群體可以通過結合他們的智慧和彼此溝通來成就偉大的事情,但他們遭受的每一次損失都會對群體及其生存能力造成更大的損害。
也就是說,您已經擁有了開始工作所需的工具。下一章將介紹分散式 OTP 應用程式的概念 — 這是一種為硬體故障提供接管和故障轉移機制的東西,但不是一般的分佈;它更像是重生你死去的殭屍,而不是其他任何東西。