熊、ETS、甜菜

我們一直以來不斷重複做的事情,就是將某種儲存裝置實作為一個程序。我們做過用來儲存東西的冰箱、建立用來註冊程序的 regis、看過鍵/值儲存等等。如果我們是採用物件導向設計的程式設計師,我們會有許多到處漂浮的單例,以及特殊的儲存類別等等。事實上,將像是 dict 和 gb_trees 等資料結構包裝在程序中,有點類似這樣。
將資料結構保存在程序中,在很多情況下其實是可行的 — 只要我們真的需要該資料在程序內執行某些任務,像是內部狀態等等。我們有很多有效的使用案例,我們不應該改變這種做法。不過,有一種情況下它可能不是最佳選擇:當程序為了與其他程序分享資料而持有資料結構,而沒有其他用途時。
我們寫過的一個應用程式就犯了這個錯誤。你能猜到是哪個嗎?當然可以;我在上一章的結尾提到了:regis 需要重寫。並不是說它不能運作或無法好好完成工作,而是因為它作為一個閘道,與潛在大量的其他程序分享資料,因此存在架構上的問題。
你看,regis 是在 Process Quest(以及任何會使用它的東西)中進行訊息傳遞的中心應用程式,而且幾乎每個傳送到已命名程序的訊息都必須經過它。這意味著,即使我們非常小心地讓我們的應用程式透過獨立的 actors 達到高度並行,並確保我們的監督結構能夠擴展,我們所有的操作都將取決於一個中心的 regis 程序,而它必須逐一回覆訊息。
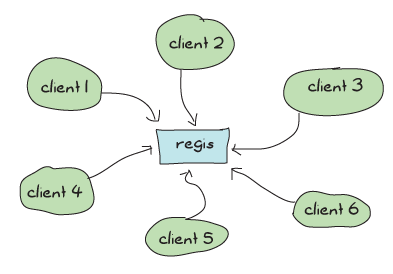
如果我們有很多訊息傳遞正在進行,regis 可能會越來越忙碌,如果需求夠高,我們整個系統將會變成循序處理並變慢。這很糟糕。
注意:我們沒有直接證據證明 regis 是 Process Quest 中的瓶頸 — 事實上,相較於許多其他實際應用程式,Process Quest 的訊息傳遞量非常少。如果我們將 regis 用於需要更多訊息傳遞和查找的應用,那麼問題會更明顯。
我們能解決這個問題的少數方法,要嘛是將 regis 分割成子程序,透過分片資料來加快查找速度,要嘛就是找到一種方法將資料儲存在某個資料庫中,使其能夠平行且並行存取資料。雖然第一種方法很有趣可以探索,但我們會選擇較簡單的方法,也就是後者。
Erlang 有一種稱為 ETS(Erlang Term Storage)表的東西。ETS 表是一種高效能的記憶體資料庫,包含在 Erlang 虛擬機器中。它位於虛擬機器的一個允許破壞性更新,且垃圾回收機制不敢接近的部分。它們通常很快,而且對於 Erlang 程式設計師來說,當程式碼的某些部分變得太慢時,這是一個相當容易最佳化的方法。
ETS 表允許有限的讀寫並行性(比程序的信箱完全沒有並行性要好得多),這種方式可以讓我們最佳化掉很多痛苦。
別喝太多 Kool-Aid
雖然 ETS 表是一種不錯的最佳化方法,但仍應謹慎使用。預設情況下,VM 限制為 1400 個 ETS 表。雖然可以更改這個數字 (erl -env ERL_MAX_ETS_TABLES Number),但這個預設的低限制值是一個很好的警訊,表示您應該盡量避免每個程序都有一個表。
但在我們重寫 regis 以使用 ETS 之前,我們應該先嘗試了解一些 ETS 的原理。
ETS 的概念
ETS 表實作為 ets 模組中的 BIF。ETS 的主要設計目標是提供一種在 Erlang 中儲存大量資料的方法,具有恆定的存取時間(函式資料結構通常傾向於對數存取時間),並使此類儲存看起來像是實作為程序,以保持它們的使用簡單且符合慣用方式。
注意:讓表看起來像程序並不表示您可以產生它們或連結到它們,而是表示它們可以遵守無共享的語義、將呼叫包裝在函式介面之後、讓它們處理任何 Erlang 原生資料類型,並可以給它們命名(在單獨的註冊表中)等等。
所有 ETS 表原生儲存包含您想要的任何內容的 Erlang 元組,其中一個元組元素將作為您用來排序的主要索引鍵。也就是說,擁有形式為 {Name, Age, PhoneNumber, Email} 的人員元組將讓您擁有一個類似以下的表
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
...
因此,如果我們說我們希望該表的索引為電子郵件地址,我們可以透過告訴 ETS 將索引鍵位置設定為 4 來做到這一點(當我們開始實際的 ETS 函式呼叫時,我們會看到如何做到這一點)。一旦您決定了索引鍵,您可以選擇不同的方式將資料儲存到表中
- set
- set 表會告訴您,每個索引鍵實例都必須是唯一的。上面的資料庫中不能有重複的電子郵件。當您需要使用具有恆定時間存取的標準鍵/值儲存時,set 非常適合。
- ordered_set
- 每個表仍然只能有一個索引鍵實例,但是
ordered_set增加了一些其他有趣的屬性。第一個是ordered_set表中的元素將會排序(誰會想到?!)。該表的第一個元素是最小的元素,最後一個元素是最大的元素。如果您迭代地遍歷一個表(一次又一次地跳到下一個元素),這些值應該是遞增的,這對於set表不一定是真的。當您頻繁地需要操作範圍時(我想要條目 12 到 50!),有序 set 表非常適合。然而,它們的缺點是存取時間較慢 (O(log N),其中 N 是儲存的物件數量)。 - bag
- bag 表可以有多個具有相同索引鍵的條目,只要這些元組本身不同即可。這表示該表可以同時擁有
{key, some, values}和{key, other, values}而不會有問題,這對於 set 來說是不可能的(它們具有相同的索引鍵)。但是,您不能在表中擁有兩個{key, some, values},因為它們將完全相同。 - duplicate_bag
- 這種型別的表與
bag表類似,但允許在同一個表中多次持有完全相同的元組。
注意:對於所有操作,ordered_set 表會將值 1 和 1.0 視為相同。其他表會將它們視為不同。
最後一個要了解的通用概念是,ETS 表將具有控制程序的概念,很像 socket。當一個程序呼叫啟動新 ETS 表的函式時,該程序就是該表的所有者。
預設情況下,只有表的所有者可以寫入它,但每個人都可以從中讀取。這稱為受保護的權限層級。您也可以選擇將權限設定為公開,讓每個人都可以讀取和寫入,或設定為私有,讓只有所有者可以讀取或寫入。

表的所有權概念更深入一層。ETS 表與程序緊密連結。如果程序死掉,表也會消失(以及它的所有內容)。但是,該表可以像我們對 socket 和它們的控制程序所做的那樣被贈與,或者可以確定繼承者,以便如果所有者程序死掉,該表會自動贈與給繼承者程序。
ETS 打電話回家
若要啟動 ETS 表,必須呼叫函式 ets:new/2。該函式會接收參數 Name,然後接收選項列表。作為回報,您會收到使用該表所需的唯一識別碼,這與程序的 Pid 相當。選項可以是以下任何一項
Type = set | ordered_set | bag | duplicate_bag- 設定您要使用的表類型,如上一節所述。預設值為
set。 Access = private | protected | public- 讓我們設定表上的權限,如先前所述。預設選項為
protected。 named_table- 有趣的是,如果您呼叫
ets:new(some_name, []),您將會啟動一個受保護的 set 表,但沒有名稱。若要將名稱用作聯絡表的方式(並使其唯一),必須將選項named_table傳遞給函式。否則,表的名稱僅用於文件用途,並會出現在諸如ets:i()等函式中,這些函式會印出系統中所有 ETS 表的相關資訊。 {keypos, Position}- 您可能(且應該)記得,ETS 表透過儲存元組來運作。參數 Position 保留一個從 1 到 N 的整數,告訴您每個元組的哪個元素應作為資料庫表的主索引鍵。預設索引鍵位置設定為 1。這表示如果您使用紀錄,則必須小心,因為每個紀錄的第一個元素始終會是紀錄的名稱(請記住它們在元組形式中的樣子)。如果您想使用任何欄位作為索引鍵,請使用
{keypos, #RecordName.FieldName},因為它會傳回 FieldName 在紀錄的元組表示中的位置。 {heir, Pid, Data} | {heir, none}- 如上一節所述,ETS 表有一個程序作為其父程序。如果該程序死掉,該表也會消失。如果附加到表的資料是您可能想要保持存活的東西,那麼定義繼承者會很有用。如果附加到表的程序死掉,繼承者會收到一則訊息,上面寫著
{'ETS-TRANSFER', TableId, FromPid, Data}',其中 Data 是最初定義選項時傳遞的元素。該表會自動由繼承者繼承。預設情況下,沒有定義繼承者。可以在稍後透過呼叫ets:setopts(Table, {heir, Pid, Data})或ets:setopts(Table, {heir, none})來定義或變更繼承者。如果您只是想贈與該表,請呼叫ets:give_away/3。 {read_concurrency, true | false}- 這是一個最佳化表以用於讀取並行性的選項。將此選項設定為 true 表示讀取變得非常便宜,但切換到寫入的成本會高得多。基本上,當您執行大量讀取和少量寫入並且需要額外的效能提升時,應啟用此選項。如果您執行一些讀取、一些寫入且它們是交錯的,則使用此選項甚至可能會損害效能。
{write_concurrency, true | false}- 通常,寫入到表會鎖定整個表,直到寫入完成之前,沒有其他人可以存取它,無論是讀取還是寫入。將此選項設定為 'true' 可讓讀取和寫入同時完成,而不會影響 ETS 的 ACID 屬性。然而,這樣做會降低單一程序循序寫入的效能,以及並行讀取的能力。當寫入和讀取都以大量爆發形式出現時,您可以將此選項與 'read_concurrency' 結合使用。
compressed- 使用此選項可讓表中的資料針對大多數欄位進行壓縮,但主索引鍵除外。當檢查整個表的元素時,這會以效能為代價,我們會在接下來的函式中看到。
接著,表格建立的反面就是表格銷毀。對於銷毀表格,只需要呼叫 ets:delete(Table),其中 Table 可以是表格 ID 或具名表格的名稱。如果要從表格中刪除單一條目,則需要非常相似的函式呼叫: ets:delete(Table, Key)。
處理基本表格還需要兩個函式:insert(Table, ObjectOrObjects) 和 lookup(Table, Key)。在 insert/2 的情況下,ObjectOrObjects 可以是要插入的單個元組或元組列表。
1> ets:new(ingredients, [set, named_table]).
ingredients
2> ets:insert(ingredients, {bacon, great}).
true
3> ets:lookup(ingredients, bacon).
[{bacon,great}]
4> ets:insert(ingredients, [{bacon, awesome}, {cabbage, alright}]).
true
5> ets:lookup(ingredients, bacon).
[{bacon,awesome}]
6> ets:lookup(ingredients, cabbage).
[{cabbage,alright}]
7> ets:delete(ingredients, cabbage).
true
8> ets:lookup(ingredients, cabbage).
[]
您會注意到 lookup 函式會返回一個列表。它將對所有類型的表格執行此操作,即使基於集合的表格最多只會返回一個項目。這只是意味著即使您使用包或重複包(對於單個鍵可能會返回多個值),您也應該能夠以通用方式使用 lookup 函式。
上面的程式碼片段中發生的另一件事是,插入兩次相同的鍵會覆蓋它。這將始終發生在集合和有序集合中,但不會發生在包或重複包中。如果您想避免這種情況,可以使用 ets:insert_new/2 函式,因為它只會在元素尚未在表格中時插入元素。
注意: ETS 表格中的元組不必都是相同大小,儘管這樣做應被視為良好的習慣。但是,元組的大小至少必須與鍵位置的大小相同(或更大)。
如果只需要提取元組的一部分,還有另一個可用的查詢函式。該函式是 lookup_element(TableID, Key, PositionToReturn),它將返回匹配的元素(如果有多個具有包或重複包表格的元素,則返回它們的列表)。如果該元素不存在,則函式會因 badarg 為原因而發生錯誤。
在任何情況下,讓我們再試試一個包
9> TabId = ets:new(ingredients, [bag]).
16401
10> ets:insert(TabId, {bacon, delicious}).
true
11> ets:insert(TabId, {bacon, fat}).
true
12> ets:insert(TabId, {bacon, fat}).
true
13> ets:lookup(TabId, bacon).
[{bacon,delicious},{bacon,fat}]
由於這是一個包,即使我們插入了兩次,{bacon, fat} 也只會存在一次,但您可以看到我們仍然可以有多個 'bacon' 條目。這裡要看的另一件事是,如果沒有傳入 named_table 選項,我們必須使用 TableId 來使用該表格。
注意:如果在複製這些範例的過程中您的 shell 崩潰,則表格將會消失,因為它們的父處理程序(shell)已消失。
我們可以使用的最後一個基本操作將是關於逐一遍歷表格。如果您注意的話,ordered_set 表格最適合此用途
14> ets:new(ingredients, [ordered_set, named_table]).
ingredients
15> ets:insert(ingredients, [{ketchup, "not much"}, {mustard, "a lot"}, {cheese, "yes", "goat"}, {patty, "moose"}, {onions, "a lot", "caramelized"}]).
true
16> Res1 = ets:first(ingredients).
cheese
17> Res2 = ets:next(ingredients, Res1).
ketchup
18> Res3 = ets:next(ingredients, Res2).
mustard
19> ets:last(ingredients).
patty
20> ets:prev(ingredients, ets:last(ingredients)).
onions
如您所見,元素現在按排序順序排列,並且可以一個接一個地存取,包括向前和向後。哦,對了,然後我們需要看看在邊界條件下會發生什麼
21> ets:next(ingredients, ets:last(ingredients)). '$end_of_table' 22> ets:prev(ingredients, ets:first(ingredients)). '$end_of_table'
當您看到以 $ 開頭的原子時,您應該知道它們是 OTP 團隊根據慣例選擇的一些特殊值,以告訴您一些事情。每當您嘗試在表格外進行迭代時,您都會看到這些 $end_of_table 原子。
因此,我們知道如何將 ETS 用作非常基本的鍵值儲存。現在還有更進階的用途,當我們需要的不僅僅是鍵的匹配時。
符合您的需求

在從更特殊的機制尋找記錄時,可以使用大量 ETS 函式。
當我們考慮到這一點時,選擇內容的最佳方式是使用模式比對,對吧?理想的情況是能夠以某種方式將要比對的模式儲存在變數中(或作為資料結構),將其傳遞給某些 ETS 函式,並讓該函式執行其操作。
這稱為 *高階模式比對*,遺憾的是,Erlang 中無法使用它。事實上,很少有語言擁有它。相反,Erlang 有一些 Erlang 程式設計師同意使用的子語言,該子語言被用來將模式比對描述為一堆常規資料結構。
此表示法基於元組,以便與 ETS 完美契合。它只是讓您指定變數(常規變數和「不在乎」變數),這些變數可以與元組混合以執行模式比對。變數寫為 '$0'、'$1'、'$2' 等(數字並不重要,除非在您取得結果的方式中),對於常規變數。「不在乎」變數可以寫為 '_'。所有這些原子都可以採用元組形式,例如
{items, '$3', '$1', '_', '$3'}
這大致相當於說 {items, C, A, _, C} 使用常規模式比對。因此,您可以猜到第一個元素需要是原子 items,元組的第二個和第五個位置需要相同,等等。
為了在更實際的設定中使用此表示法,可以使用兩個函式:match/2 和 match_object/2(也有可用的 match/3 和 match_object/3,但它們的使用超出了本章的範圍,建議讀者查閱文件以了解詳細資訊)。前者將返回模式的變數,而後者將返回與模式匹配的整個條目。
1> ets:new(table, [named_table, bag]).
table
2> ets:insert(table, [{items, a, b, c, d}, {items, a, b, c, a}, {cat, brown, soft, loveable, selfish}, {friends, [jenn,jeff,etc]}, {items, 1, 2, 3, 1}]).
true
3> ets:match(table, {items, '$1', '$2', '_', '$1'}).
[[a,b],[1,2]]
4> ets:match(table, {items, '$114', '$212', '_', '$6'}).
[[d,a,b],[a,a,b],[1,1,2]]
5> ets:match_object(table, {items, '$1', '$2', '_', '$1'}).
[{items,a,b,c,a},{items,1,2,3,1}]
6> ets:delete(table).
true
關於 match/2-3 作為函式的優點在於,它只會返回嚴格來說必須返回的內容。這很有用,因為如前所述,ETS 表格遵循無共享的理想。如果您有非常大的記錄,則僅複製必要的欄位可能是一件好事。無論如何,您也會注意到,雖然變數中的數字沒有明確的含義,但它們的順序很重要。在返回值的最終列表中,模式將使綁定到 $114 的值始終在綁定到 $6 的值之後。如果沒有任何匹配,則會返回空列表。
您也可能想要根據此類模式比對刪除條目。在這些情況下,您需要使用函式 ets:match_delete(Table, Pattern)。

這些都很好,讓我們可以放入任何種類的值,以奇怪的方式執行基本的模式比對。如果可以擁有諸如比較和範圍、明確格式化輸出的方式(也許列表不是我們想要的)等功能,那將是非常棒的。哦,等等,您可以!
您已被選中
當我們獲得更等同於真實函式標頭層級的模式比對(包括非常簡單的防護)時,就會出現這種情況。如果您以前使用過 SQL 資料庫,您可能已經看到過執行查詢的方法,其中您比較大於、等於、小於其他元素的元素。這是我們在這裡想要的好東西。
因此,Erlang 背後的人們採用了我們看到的用於比對的語法,並以瘋狂的方式對其進行擴充,直到它足夠強大。遺憾的是,他們也使它難以閱讀。以下是它的樣子
[{{'$1','$2',<<1>>,'$3','$4'},
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}],
['$1']},
{{'$1','$2',<<1>>,'$3','$4'},
[{'<','$3',4.0},{is_float,'$3'}],
['$1']}]
這非常難看,不是您希望您的孩子看到的資料結構。信不信由你,我們將學習如何編寫這些稱為 *比對規格* 的東西。不是以這種形式,不,這會有點太難而沒有理由。不過,我們仍然會學習如何閱讀它們!以下是它從更高層級視角的樣子
[{InitialPattern1, Guards1, ReturnedValue1},
{InitialPattern2, Guards2, ReturnedValue2}].
或從更高的視角來看
[Clause1, Clause2]
因此,是的,諸如此類的東西大致代表函式標頭中的模式、防護,然後是函式的主體。格式仍然限制為初始模式的 '$N' 變數,與比對函式的模式完全相同。新部分是防護模式,允許執行與常規防護非常相似的操作。如果我們仔細查看防護 [{'<','$3',4.0},{is_float,'$3'}],我們可以看到它與作為防護的 ... when Var < 4.0, is_float(Var) -> ... 非常相似。
下一個防護,這次更複雜,是
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}]
翻譯它會給我們一個看起來像 ... when Var4 > 150 andalso Var4 < 500, Var2 == meat orelse Var2 == dairy -> ... 的防護。了解了嗎?
每個運算符或防護函式都使用前綴語法,這意味著我們使用 {FunctionOrOperator, Arg1, ..., ArgN} 的順序。因此,is_list(X) 變成 {is_list, '$1'},X andalso Y 變成 {'andalso', X, Y},依此類推。諸如 andalso、orelse 和 == 等運算符之類的保留關鍵字需要放入原子中,這樣 Erlang 剖析器才不會阻塞它們。
模式的最後一部分是您想要返回的內容。只需將您需要的變數放在其中即可。如果您想返回比對規格的完整輸入,請使用變數 '$_' 執行此操作。有關比對規格的完整規格可以在 Erlang 文件中找到。
正如我之前所說,我們不會學習如何以這種方式編寫模式,有更好的方法可以做到。ETS 隨附稱為 *剖析轉換* 的東西。剖析轉換是一種未經記錄的(因此不受 OTP 團隊支援)方式,可以在編譯階段中途存取 Erlang 剖析樹。它們讓勇敢的 Erlang 程式設計師將模組中的程式碼轉換為新的替代形式。剖析轉換幾乎可以是任何東西,並且可以將現有的 Erlang 程式碼更改為幾乎任何其他東西,只要它不更改語言的語法或其符號。
需要為每個需要它的模組手動啟用 ETS 隨附的剖析轉換。在模組中執行此操作的方式如下
-module(SomeModule).
-include_lib("stdlib/include/ms_transform.hrl").
...
some_function() ->
ets:fun2ms(fun(X) when X > 4 -> X end).
行 -include_lib("stdlib/include/ms_transform.hrl"). 包含一些特殊程式碼,每當在模組中使用 ets:fun2ms(SomeLiteralFun) 時,它都會覆寫其含義。剖析轉換不是高階函式,而是分析 fun 中的內容(模式、防護和返回值),移除對 ets:fun2ms/1 的函式呼叫,並將所有內容替換為實際的比對規格。很奇怪,對吧?最好的是,由於這發生在編譯時,因此使用這種方法沒有任何開銷。
這次我們可以在 shell 中嘗試它,而無需包含檔案
1> ets:fun2ms(fun(X) -> X end).
[{'$1',[],['$1']}]
2> ets:fun2ms(fun({X,Y}) -> X+Y end).
[{{'$1','$2'},[],[{'+','$1','$2'}]}]
3> ets:fun2ms(fun({X,Y}) when X < Y -> X+Y end).
[{{'$1','$2'},[{'<','$1','$2'}],[{'+','$1','$2'}]}]
4> ets:fun2ms(fun({X,Y}) when X < Y, X rem 2 == 0 -> X+Y end).
[{{'$1','$2'},
[{'<','$1','$2'},{'==',{'rem','$1',2},0}],
[{'+','$1','$2'}]}]
5> ets:fun2ms(fun({X,Y}) when X < Y, X rem 2 == 0; Y == 0 -> X end).
[{{'$1','$2'},
[{'<','$1','$2'},{'==',{'rem','$1',2},0}],
['$1']},
{{'$1','$2'},[{'==','$2',0}],['$1']}]
所有這些!現在它們寫起來如此輕鬆!當然,這些 fun 也更容易閱讀。那麼本節開頭的複雜範例呢?以下是它作為 fun 的樣子
6> ets:fun2ms(fun({Food, Type, <<1>>, Price, Calories}) when Calories > 150 andalso Calories < 500, Type == meat orelse Type == dairy; Price < 4.00, is_float(Price) -> Food end).
[{{'$1','$2',<<1>>,'$3','$4'},
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}],
['$1']},
{{'$1','$2',<<1>>,'$3','$4'},
[{'<','$3',4.0},{is_float,'$3'}],
['$1']}]
乍看之下,它並非完全有意義,但至少當變數實際上可以使用名稱而不是數字時,更容易弄清楚它的含義。需要注意的一件事是,並非所有 fun 都是有效的比對規格
7> ets:fun2ms(fun(X) -> my_own_function(X) end).
Error: fun containing the local function call 'my_own_function/1' (called in body) cannot be translated into match_spec
{error,transform_error}
8> ets:fun2ms(fun(X,Y) -> ok end).
Error: ets:fun2ms requires fun with single variable or tuple parameter
{error,transform_error}
9> ets:fun2ms(fun([X,Y]) -> ok end).
Error: ets:fun2ms requires fun with single variable or tuple parameter
{error,transform_error}
10> ets:fun2ms(fun({<<X/binary>>}) -> ok end).
Error: fun head contains bit syntax matching of variable 'X', which cannot be translated into match_spec
{error,transform_error}
函式標頭需要在單個變數或元組上進行比對,沒有非防護函式可以作為返回值的一部分呼叫,不允許從二進位值中指派值,等等。在 shell 中嘗試各種操作,看看您可以執行哪些操作。
別喝太多 Kool-Aid
一個像 ets:fun2ms 這樣的函式聽起來真是太棒了,對吧!但你必須小心使用它。它的一個問題是,如果 ets:fun2ms 在 shell 環境中可以處理動態 fun(你可以傳遞 fun,它會直接處理掉),這在編譯後的模組中是不可能的。
這是因為 Erlang 有兩種 fun:shell fun 和模組 fun。模組 fun 會被編譯成虛擬機器可以理解的緊湊格式。它們是不透明的,無法被檢查以了解其內部結構。
另一方面,shell fun 是尚未被評估的抽象詞彙。它們的設計方式是讓 shell 可以對它們調用評估器。因此,fun2ms 函式會有兩個版本:一個用於取得編譯後的程式碼,另一個用於在 shell 環境中使用。
這沒問題,只是不同類型的 fun 不能互換使用。這表示你不能在 shell 環境中對編譯後的 fun 調用 ets:fun2ms,也不能將動態 fun 傳送到在其中調用 fun2ms 的編譯程式碼。太可惜了!
為了讓 match specification 更實用,使用它們是合理的。這可以透過使用函式 ets:select/2 來獲取結果、使用 ets:select_reverse/2 在 ordered_set 表格中反向獲取結果(對於其他類型,它與 select/2 相同)、使用 ets:select_count/2 來了解有多少結果符合規格,以及使用 ets:select_delete(Table, MatchSpec) 來刪除符合 match specification 的記錄。
讓我們試試看,首先為我們的表格定義一個 record,然後用各種商品填充它們
11> rd(food, {name, calories, price, group}).
food
12> ets:new(food, [ordered_set, {keypos,#food.name}, named_table]).
food
13> ets:insert(food, [#food{name=salmon, calories=88, price=4.00, group=meat},
13> #food{name=cereals, calories=178, price=2.79, group=bread},
13> #food{name=milk, calories=150, price=3.23, group=dairy},
13> #food{name=cake, calories=650, price=7.21, group=delicious},
13> #food{name=bacon, calories=800, price=6.32, group=meat},
13> #food{name=sandwich, calories=550, price=5.78, group=whatever}]).
true
然後我們可以嘗試選擇卡路里數低於指定數量的食物項目
14> ets:select(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = cereals,calories = 178,price = 2.79,group = bread},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = sandwich,calories = 550,price = 5.78,group = whatever}]
15> ets:select_reverse(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = sandwich,calories = 550,price = 5.78,group = whatever},
#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = cereals,calories = 178,price = 2.79,group = bread}]
或者我們想要的可能只是美味的食物
16> ets:select(food, ets:fun2ms(fun(N = #food{group=delicious}) -> N end)).
[#food{name = cake,calories = 650,price = 7.21,group = delicious}]
刪除操作有一點特別的變化。你必須在 pattern 中返回 true 而不是任何種類的值
17> ets:select_delete(food, ets:fun2ms(fun(#food{price=P}) when P > 5 -> true end)).
3
18> ets:select_reverse(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = cereals,calories = 178,price = 2.79,group = bread}]
而最後的選擇顯示,超過 $5.00 的項目已從表格中移除。
ETS 內部還有更多函式,例如將表格轉換為列表或檔案的方法(ets:tab2list/1、ets:tab2file/1、ets:file2tab/1),獲取有關所有表格的資訊(ets:i/0、ets:info(Table))。在這種情況下,強烈建議前往官方文件查閱。
還有一個名為 observer 的應用程式,其中有一個 tab 可用於視覺化管理給定 Erlang VM 上的 ETS 表格。如果你的 Erlang 是使用 wx 支援建置的,只需呼叫 observer:start() 並選擇表格檢視器 tab。在較舊的 Erlang 版本中,observer 並不存在,你可能必須改用現在已棄用的 tv 應用程式 (tv:start())。
DETS
DETS 是基於磁碟的 ETS 版本,有一些關鍵差異。
不再有 ordered_set 表格,DETS 檔案的磁碟大小限制為 2GB,並且 prev/1 和 next/1 等操作的速度和安全性都差很多。
表格的啟動和停止方式已稍作變更。透過呼叫 dets:open_file/2 來建立新的資料庫表格,並透過執行 dets:close/1 來關閉它。稍後可以透過呼叫 dets:open_file/1 來重新開啟表格。
否則,API 幾乎相同,因此可以有一種非常簡單的方法來處理在檔案中寫入和尋找資料。
別喝太多 Kool-Aid
由於 DETS 是一個僅限磁碟的資料庫,因此速度可能會很慢。你可能會覺得將 ETS 和 DETS 表格耦合到一個有點有效率的資料庫中,該資料庫同時儲存在 RAM 和磁碟上。
如果你想這麼做,查看 Mnesia 作為資料庫可能是一個好主意,它完全做著相同的事情,同時還增加了對分片、交易和分散式系統的支援。
少點閒聊,多點行動

在經歷這個相當長的章節標題(以及之前漫長的章節)之後,我們將轉向將我們帶到這裡的實際問題:更新 regis 以使其使用 ETS 並擺脫一些潛在的瓶頸。
在開始之前,我們必須考慮如何處理操作,以及哪些是安全和不安全的。應該是安全的那些是不修改任何東西並且僅限於一次查詢(而不是隨著時間推移的 3-4 次查詢)。它們可以由任何人隨時完成。其他所有與寫入表格、更新記錄、刪除記錄或以需要在多個請求中保持一致性的方式讀取記錄相關的操作都被認為是不安全的。
由於 ETS 完全沒有交易,所有不安全的操作都應由擁有該表格的程序執行。安全的應該允許公開,在擁有者程序之外完成。我們在更新 regis 時會記住這一點。
第一步是將 regis-1.0.0 複製為 regis-1.1.0。我這裡將第二個數字而不是第三個數字提升,因為我們的變更不應破壞現有的介面,嚴格來說也不是錯誤修復,因此我們只會將其視為功能升級。
在那個新目錄中,我們首先只需要操作 regis_server.erl:我們將保持介面不變,因此就結構而言,其餘部分不應需要做太多變更
%%% The core of the app: the server in charge of tracking processes.
-module(regis_server).
-behaviour(gen_server).
-include_lib("stdlib/include/ms_transform.hrl").
-export([start_link/0, stop/0, register/2, unregister/1, whereis/1,
get_names/0]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
%%%%%%%%%%%%%%%%%
%%% INTERFACE %%%
%%%%%%%%%%%%%%%%%
start_link() ->
gen_server:start_link({local, ?MODULE}, ?MODULE, [], []).
stop() ->
gen_server:call(?MODULE, stop).
%% Give a name to a process
register(Name, Pid) when is_pid(Pid) ->
gen_server:call(?MODULE, {register, Name, Pid}).
%% Remove the name from a process
unregister(Name) ->
gen_server:call(?MODULE, {unregister, Name}).
%% Find the pid associated with a process
whereis(Name) -> ok.
%% Find all the names currently registered.
get_names() -> ok.
對於公共介面,只有 whereis/1 和 get_names/0 將會變更和重寫。這是因為,如先前所述,這些是單次讀取安全操作。其餘的將需要在擁有該表格的程序中序列化。這就是到目前為止的 API。讓我們前往模組內部。
我們將使用 ETS 表格來儲存資料,因此將該表格放入 init 函式是有意義的。此外,由於我們的 whereis/1 和 get_names/0 函式將公開存取該表格(為了速度原因),命名該表格對於外部世界可以存取它來說是必要的。透過命名表格,就像我們命名程序一樣,我們可以在函式中硬式編碼名稱,而不需要傳遞 id。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%% GEN_SERVER CALLBACKS %%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
init([]) ->
?MODULE = ets:new(?MODULE, [set, named_table, protected]),
{ok, ?MODULE}.
下一個函式將是 handle_call/3,它處理在 register/2 中定義的訊息 {register, Name, Pid}。
handle_call({register, Name, Pid}, _From, Tid) ->
%% Neither the name or the pid can already be in the table
%% so we match for both of them in a table-long scan using this.
MatchSpec = ets:fun2ms(fun({N,P,_Ref}) when N==Name; P==Pid -> {N,P} end),
case ets:select(Tid, MatchSpec) of
[] -> % free to insert
Ref = erlang:monitor(process, Pid),
ets:insert(Tid, {Name, Pid, Ref}),
{reply, ok, Tid};
[{Name,_}|_] -> % maybe more than one result, but name matches
{reply, {error, name_taken}, Tid};
[{_,Pid}|_] -> % maybe more than one result, but Pid matches
{reply, {error, already_named}, Tid}
end;
這是模組中目前為止最複雜的函式。有三個基本規則需要遵守
- 一個程序不能被註冊兩次
- 一個名稱不能被使用兩次
- 如果程序沒有違反規則 1 和 2,則可以註冊程序
這就是上面的程式碼所做的。從 fun({N,P,_Ref}) when N==Name; P==Pid -> {N,P} end 衍生的 match specification 將在整個表格中尋找與我們嘗試註冊的名稱或 pid 相符的條目。如果有匹配,我們會傳回找到的名稱和 pid。這可能很奇怪,但當我們查看之後 case ... of 的 pattern 時,想要兩者是有意義的。
第一個 pattern 表示沒有找到任何東西,因此插入是好的。我們監控我們已註冊的程序(以便在失敗時取消註冊它),然後將條目新增到表格中。如果我們嘗試註冊的名稱已在表格中,則 pattern [{Name,_}|_] 將會處理它。如果匹配的是 Pid,則 pattern [{_,Pid}|_] 將會處理它。這就是傳回兩個值的原因:這樣可以更簡單地在稍後匹配整個 tuple,而不用擔心它們在 match spec 中匹配的是哪個。為什麼 pattern 的形式是 [Tuple|_] 而不是僅僅是 [Tuple]?解釋很簡單。如果我們在表格中搜尋相似的 Pid 或名稱,則傳回的列表可能是 [{NameYouWant, SomePid},{SomeName,PidYouWant}]。如果發生這種情況,則 [Tuple] 形式的 pattern match 會讓負責表格的程序崩潰並毀了你的一天。
哦,對了,不要忘記在模組中新增 -include_lib("stdlib/include/ms_transform.hrl").,否則,fun2ms 會因為奇怪的錯誤訊息而失敗
** {badarg,{ets,fun2ms,
[function,called,with,real,'fun',should,be,transformed,with,
parse_transform,'or',called,with,a,'fun',generated,in,the,
shell]}}
這就是當你忘記 include 檔案時會發生的情況。請記住此警告。過馬路前要看清楚,不要交叉水管,也不要忘記你的 include 檔案。
接下來要做的是當我們要求手動取消註冊程序時
handle_call({unregister, Name}, _From, Tid) ->
case ets:lookup(Tid, Name) of
[{Name,_Pid,Ref}] ->
erlang:demonitor(Ref, [flush]),
ets:delete(Tid, Name),
{reply, ok, Tid};
[] ->
{reply, ok, Tid}
end;
如果你查看舊版本的程式碼,這仍然很相似。概念很簡單:找到監控參考 (透過查找名稱),取消監控,然後刪除條目並繼續執行。如果該條目不存在,我們會假裝我們已將其刪除,並且每個人都會很高興。啊,我們真是不老實。
接下來是關於停止伺服器
handle_call(stop, _From, Tid) ->
%% For the sake of being synchronous and because emptying ETS
%% tables might take a bit longer than dropping data structures
%% held in memory, dropping the table here will be safer for
%% tricky race conditions, especially in tests where we start/stop
%% servers a lot. In regular code, this doesn't matter.
ets:delete(Tid),
{stop, normal, ok, Tid};
handle_call(_Event, _From, State) ->
{noreply, State}.
正如程式碼中的註解所述,我們本可以忽略該表格並讓其被垃圾回收。但是,由於我們為上一章編寫的測試套件會一直啟動和停止伺服器,因此延遲可能會有點危險。你看,這是舊版程序的時程表
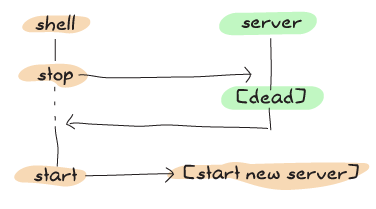
這是新版有時會發生的情況
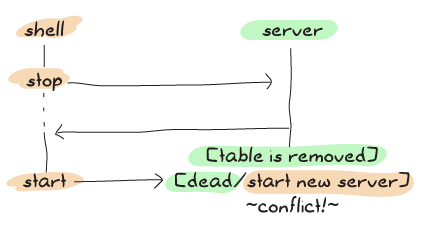
透過使用上述方案,我們在程式碼的同步部分進行更多工作,使得錯誤發生的可能性大大降低
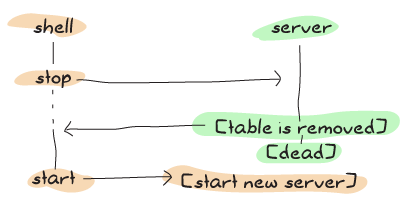
如果你不打算經常執行測試套件,你可以直接忽略整件事。我決定展示它以避免出現惱人的意外,儘管在非測試系統中,這種邊緣情況應該很少發生。
這是其餘的 OTP 回呼
handle_cast(_Event, State) ->
{noreply, State}.
handle_info({'DOWN', Ref, process, _Pid, _Reason}, Tid) ->
ets:match_delete(Tid, {'_', '_', Ref}),
{noreply, Tid};
handle_info(_Event, State) ->
{noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
我們不在意它們中的任何一個,除非收到 DOWN 訊息,這表示我們正在監控的其中一個程序已終止。當發生這種情況時,我們會根據我們在訊息中擁有的參考來刪除該條目,然後繼續。
你會注意到 code_change/3 實際上可以作為舊的 regis_server 和新的 regis_server 之間的轉換。實作此函式留給讀者作為練習。我總是討厭那些不提供解答就給讀者練習的書籍,所以這裡至少給一點提示,這樣我就不會像其他作家一樣只是個混蛋:你必須從舊版本中取得兩個 gb_trees 中的任何一個,然後使用 gb_trees:map/2 或 gb_trees 迭代器來填充新的表格,然後再繼續。可以透過相反的方式編寫降級函式。
剩下要做的就是修復我們尚未實作的兩個公共函式。當然,我們可以寫一個 %% TODO 註解,然後直接去喝酒直到忘記我們是程式設計師,但這會有點不負責任。讓我們來修復一下
%% Find the pid associated with a process
whereis(Name) ->
case ets:lookup(?MODULE, Name) of
[{Name, Pid, _Ref}] -> Pid;
[] -> undefined
end.
這一個會尋找一個名稱,並根據是否找到該條目傳回 Pid 或 undefined。請注意,我們在那裡確實使用了 regis_server (?MODULE) 作為表格名稱;這就是我們一開始使其受到保護和命名的原因。對於下一個
%% Find all the names currently registered.
get_names() ->
MatchSpec = ets:fun2ms(fun({Name, _, _}) -> Name end),
ets:select(?MODULE, MatchSpec).
我們再次使用 fun2ms 來匹配 Name 並只保留它。從表格中選擇將傳回一個列表並執行我們需要的操作。
就是這樣!你可以在 test/ 中執行測試套件來讓一切順利進行
$ erl -make ... Recompile: src/regis_server $ erl -pa ebin ... 1> eunit:test(regis_server). All 13 tests passed. ok
太棒了。我想我們可以認為我們現在非常擅長 ETS 了。
你知道接下來做什麼會很棒嗎?實際上探索 Erlang 的分散式方面。也許在我們結束 Erlang 這個野獸之前,我們可以再以一些更扭曲的方式來鍛鍊我們的思維。讓我們來看看。