遞迴
哈囉,遞迴!

有些習慣命令式和物件導向程式語言的讀者可能會想知道為什麼還沒看到迴圈。答案是「什麼是迴圈?」事實上,函數式程式語言通常不提供像 for 和 while 這樣的迴圈結構。相反地,函數式程式設計師依賴一個叫做遞迴的傻概念。
我想您還記得在入門章節中解釋的不可變變數。如果您不記得,您可以多加注意!遞迴也可以用數學概念和函數來解釋。像數值的階乘這樣的基本數學函數,就很適合用遞迴來表示。一個數字 n 的階乘是序列 1 x 2 x 3 x ... x n 的乘積,或者也可以是 n x (n-1) x (n-2) x ... x 1。舉例來說,3 的階乘是 3! = 3 x 2 x 1 = 6。4 的階乘是 4! = 4 x 3 x 2 x 1 = 24。這樣的函數可以用數學符號表示如下
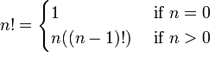
這告訴我們,如果 n 的值是 0,我們就回傳結果 1。對於任何大於 0 的值,我們回傳 n 乘以 n-1 的階乘,這個過程會一直展開到 1 為止。
4! = 4 x 3! 4! = 4 x 3 x 2! 4! = 4 x 3 x 2 x 1! 4! = 4 x 3 x 2 x 1 x 1
如何將這樣的函數從數學符號轉換為 Erlang 呢?轉換很簡單。看看符號的各個部分:n!、1 和 n((n-1)!),然後是 if。這裡我們有一個函數名稱 (n!)、保護 (if) 和函數體 (1 和 n((n-1)!))。我們會將 n! 重新命名為 fac(N) 來限制一下語法,然後我們得到以下程式碼
-module(recursive). -export([fac/1]). fac(N) when N == 0 -> 1; fac(N) when N > 0 -> N*fac(N-1).
現在這個階乘函數就完成了!它和數學定義很像,真的。藉由模式匹配的幫助,我們可以將定義縮短一點
fac(0) -> 1; fac(N) when N > 0 -> N*fac(N-1).
所以對於一些本質上是遞迴的數學定義來說,這很快速又簡單。我們迴圈了!遞迴的定義可以用一句話來概括:「一個呼叫自己的函數」。然而,我們需要一個停止條件(真正的術語是基本情況),否則我們會無限迴圈。在我們的例子中,停止條件是當 n 等於 0 時。在那一點,我們不再讓我們的函數呼叫自己,它就在那裡停止執行。
長度
讓我們試著讓它稍微更實用一點。我們將實作一個函數來計算一個列表包含多少個元素。所以我們從一開始就知道我們需要
- 一個基本情況;
- 一個呼叫自己的函數;
- 一個要用來測試我們函數的列表。
對於大多數遞迴函數,我發現先寫基本情況比較容易:要找出長度,我們能擁有的最簡單輸入是什麼?當然,一個空列表是最簡單的,長度為 0。所以讓我們在處理長度時記住 [] = 0 這個概念。然後,下一個最簡單的列表長度為 1:[_] = 1。這聽起來足以開始我們的定義。我們可以把它寫下來
len([]) -> 0; len([_]) -> 1.
太棒了!我們可以計算列表的長度,假設長度是 0 或 1!真的很實用。嗯,當然它沒用,因為它還不是遞迴的,這讓我們來到最難的部分:擴展我們的函數,讓它針對長度大於 1 或 0 的列表呼叫自己。之前提到,列表的定義是遞迴的,形式為 [1 | [2| ... [n | []]]]。這表示我們可以利用 [H|T] 模式來匹配一個或多個元素的列表,因為長度為 1 的列表會被定義為 [X|[]],而長度為 2 的列表會被定義為 [X|[Y|[]]]。注意第二個元素本身就是一個列表。這表示我們只需要計算第一個,並且函數可以在第二個元素上呼叫自己。假設列表中每個值都算作長度為 1,則函數可以重新寫成以下方式
len([]) -> 0; len([_|T]) -> 1 + len(T).
現在您有了自己的遞迴函數來計算列表的長度。為了看看 len/1 在執行時的行為,讓我們在一個給定的列表上試試看,例如 [1,2,3,4]
len([1,2,3,4]) = len([1 | [2,3,4])
= 1 + len([2 | [3,4]])
= 1 + 1 + len([3 | [4]])
= 1 + 1 + 1 + len([4 | []])
= 1 + 1 + 1 + 1 + len([])
= 1 + 1 + 1 + 1 + 0
= 1 + 1 + 1 + 1
= 1 + 1 + 2
= 1 + 3
= 4
這是正確的答案。恭喜您在 Erlang 中寫出您的第一個有用的遞迴函數!

尾遞迴的長度
您可能已經注意到,對於一個包含 4 個項目的列表,我們將函數呼叫展開為一個由 5 個加法組成的單一鏈。雖然這對於短列表來說沒有問題,但如果您的列表包含數百萬個值,這可能會變成一個問題。您不會希望為了這麼簡單的計算,在記憶體中保留數百萬個數字。這是一種浪費,而且有更好的方法。這時就要提到尾遞迴。
尾遞迴是一種將上述線性過程(隨著元素數量增長)轉換為迭代過程(實際上沒有任何增長)的方法。為了讓函數呼叫是尾遞迴,它需要是「單獨的」。讓我解釋一下:是什麼讓我們先前的呼叫增長,是因為第一部分的答案取決於評估第二部分。1 + len(Rest) 的答案需要找到 len(Rest) 的答案。函數 len(Rest) 本身也需要找到另一個函數呼叫的結果。加法會堆疊起來,直到找到最後一個,然後才會計算出最終結果。尾遞迴的目標是減少它們發生時的堆疊操作。
為了實現這個目標,我們需要在函數中保存一個額外的臨時變數作為參數。我將借助階乘函數來說明這個概念,但是這次將它定義為尾遞迴。前面提到的臨時變數有時稱為累加器,用作儲存我們計算結果的位置,以限制呼叫的增長。
tail_fac(N) -> tail_fac(N,1). tail_fac(0,Acc) -> Acc; tail_fac(N,Acc) when N > 0 -> tail_fac(N-1,N*Acc).
在這裡,我定義了 tail_fac/1 和 tail_fac/2。這樣做的原因是 Erlang 不允許函數中的預設引數(不同的 arity 表示不同的函數),所以我們手動完成。在這個特定的例子中,tail_fac/1 的作用類似於對尾遞迴函數 tail_fac/2 的抽象。關於 tail_fac/2 的隱藏累加器的細節無人關心,所以我們只會從我們的模組匯出 tail_fac/1。當執行這個函數時,我們可以將它展開為
tail_fac(4) = tail_fac(4,1) tail_fac(4,1) = tail_fac(4-1, 4*1) tail_fac(3,4) = tail_fac(3-1, 3*4) tail_fac(2,12) = tail_fac(2-1, 2*12) tail_fac(1,24) = tail_fac(1-1, 1*24) tail_fac(0,24) = 24
看出差異了嗎?現在我們永遠不需要在記憶體中保存超過兩個項目:空間使用是恆定的。計算 4 的階乘所佔用的空間,與計算 100 萬的階乘所佔用的空間相同(如果我們忽略 4! 在其完整表示中是一個比 1M! 小的數字)。
有了尾遞迴階乘的範例後,您可能會看到這種模式如何應用於我們的 len/1 函數。我們需要做的就是讓我們的遞迴呼叫「單獨」。如果您喜歡視覺範例,只要想像您要將 +1 部分放入函數呼叫中,方法是加入一個參數
len([]) -> 0; len([_|T]) -> 1 + len(T).
變成
tail_len(L) -> tail_len(L,0). tail_len([], Acc) -> Acc; tail_len([_|T], Acc) -> tail_len(T,Acc+1).
現在您的長度函數是尾遞迴的。
更多遞迴函數

我們將編寫更多遞迴函數,只是為了更習慣一下。畢竟,遞迴是 Erlang 中唯一存在的迴圈結構(除了列表推導式),它是最需要理解的重要概念之一。它在您之後嘗試的任何其他函數式程式語言中也很有用,所以請記住!
我們將編寫的第一個函數是 duplicate/2。這個函數將一個整數作為它的第一個參數,然後將任何其他項目作為它的第二個參數。然後它會建立一個列表,其中包含由整數指定的項目副本。和之前一樣,先考慮基本情況可能會幫助您開始。對於 duplicate/2,要求重複某個項目 0 次是最基本的事情。我們所要做的就是回傳一個空列表,無論項目是什麼。其他所有情況都需要透過呼叫函數本身來嘗試到達基本情況。我們也會禁止整數的負值,因為您不能將某個東西重複 -n 次
duplicate(0,_) ->
[];
duplicate(N,Term) when N > 0 ->
[Term|duplicate(N-1,Term)].
一旦找到基本的遞迴函數,就可以更輕鬆地將其轉換為尾遞迴函數,方法是將列表的建構移至臨時變數
tail_duplicate(N,Term) ->
tail_duplicate(N,Term,[]).
tail_duplicate(0,_,List) ->
List;
tail_duplicate(N,Term,List) when N > 0 ->
tail_duplicate(N-1, Term, [Term|List]).
成功!我想在這裡稍微換個話題,將尾遞迴與 while 迴圈做個類比。我們的 tail_duplicate/2 函數具有 while 迴圈的所有常用部分。如果我們要想像在一個虛構的、具有類似 Erlang 語法的語言中執行 while 迴圈,我們的函數可能看起來像這樣
function(N, Term) ->
while N > 0 ->
List = [Term|List],
N = N-1
end,
List.
請注意,在虛構語言和 Erlang 中,所有元素都在那裡。只有它們的位置會改變。這表明,一個正確的尾遞迴函數類似於一個迭代過程,就像一個 while 迴圈一樣。
當我們藉由編寫一個 reverse/1 函數來比較遞迴函數和尾遞迴函數時,我們還可以「發現」一個有趣的屬性,這個函數將會反轉一個項目列表。對於這樣的函數,基本情況是一個空列表,對於它我們沒有什麼可以反轉的。當這種情況發生時,我們可以回傳一個空列表。其他所有可能性都應該像 duplicate/2 那樣,透過呼叫自身來嘗試趨向基本情況。我們的函數將透過模式匹配 [H|T] 來迭代列表,然後將 H 放在列表的其餘部分之後
reverse([]) -> []; reverse([H|T]) -> reverse(T)++[H].
在長列表中,這將是一場真正的惡夢:我們不僅會堆疊我們所有的附加操作,而且我們還需要為每個附加操作遍歷整個列表,直到最後一個附加操作!對於視覺讀者來說,許多檢查可以表示為
reverse([1,2,3,4]) = [4]++[3]++[2]++[1]
↑ ↵
= [4,3]++[2]++[1]
↑ ↑ ↵
= [4,3,2]++[1]
↑ ↑ ↑ ↵
= [4,3,2,1]
這時尾遞迴就會派上用場。因為我們將使用累加器,並且每次都會在累加器中加入一個新的 head,所以我們的列表會自動反轉。首先讓我們看看實作
tail_reverse(L) -> tail_reverse(L,[]). tail_reverse([],Acc) -> Acc; tail_reverse([H|T],Acc) -> tail_reverse(T, [H|Acc]).
如果我們以類似於正常版本的方式表示這個,我們會得到
tail_reverse([1,2,3,4]) = tail_reverse([2,3,4], [1])
= tail_reverse([3,4], [2,1])
= tail_reverse([4], [3,2,1])
= tail_reverse([], [4,3,2,1])
= [4,3,2,1]
這表示,反轉列表所造訪的元素數量現在是線性的:我們不僅避免了堆疊的增長,而且我們也以更有效率的方式執行我們的操作!
另一個可以實作的函式是 sublist/2,它接收一個列表 L 和一個整數 N,並返回列表的前 N 個元素。舉例來說,sublist([1,2,3,4,5,6],3) 會返回 [1,2,3]。同樣地,基本情況是嘗試從列表中取得 0 個元素。然而要小心,因為 sublist/2 有點不同。當傳入的列表為空時,你有第二個基本情況!如果我們不檢查空列表,當呼叫 recursive:sublist([1],2). 時會拋出錯誤,而我們想要的結果是 [1]。一旦定義好這一點,函式的遞迴部分只需要遍歷列表,在遍歷過程中保留元素,直到遇到其中一個基本情況。
sublist(_,0) -> []; sublist([],_) -> []; sublist([H|T],N) when N > 0 -> [H|sublist(T,N-1)].
這可以像之前一樣轉換為尾遞迴形式。
tail_sublist(L, N) -> tail_sublist(L, N, []).
tail_sublist(_, 0, SubList) -> SubList;
tail_sublist([], _, SubList) -> SubList;
tail_sublist([H|T], N, SubList) when N > 0 ->
tail_sublist(T, N-1, [H|SubList]).
這個函式有一個缺陷。一個致命的缺陷! 我們使用一個列表作為累加器,方式與我們反轉列表的方式完全相同。如果你直接編譯這個函式,sublist([1,2,3,4,5,6],3) 不會返回 [1,2,3],而是 [3,2,1]。我們唯一能做的就是取得最終結果,然後自己反轉它。只要更改 tail_sublist/2 的呼叫,並保持我們所有的遞迴邏輯不變即可。
tail_sublist(L, N) -> reverse(tail_sublist(L, N, [])).
最終結果的順序將會正確。在尾遞迴呼叫之後反轉列表似乎是在浪費時間,而你說對了一部分(我們仍然可以藉此節省記憶體)。在較短的列表上,你可能會發現你的程式碼使用正常的遞迴呼叫會比使用尾遞迴呼叫更快,但隨著你的資料集增長,反轉列表的負擔會相對較輕。
注意: 你應該使用 lists:reverse/1,而不是編寫自己的 reverse/1 函式。它在尾遞迴呼叫中被使用得非常頻繁,以至於 Erlang 的維護者和開發人員決定將其變成一個 BIF。你的列表現在可以從極快的反轉中受益(這歸功於用 C 語言編寫的函式),這將使反轉的缺點變得不那麼明顯。本章的其餘程式碼將使用我們自己的反轉函式,但在那之後,你不應該再使用它了。
為了更進一步,我們將編寫一個壓縮 (zipping) 函式。壓縮函式會接收兩個長度相同的列表作為參數,並將它們合併為一個元組列表,每個元組都包含兩個項。我們自己的 zip/2 函式將會以這種方式運作。
1> recursive:zip([a,b,c],[1,2,3]).
[{a,1},{b,2},{c,3}]
由於我們希望參數的長度相同,因此基本情況是壓縮兩個空列表。
zip([],[]) -> [];
zip([X|Xs],[Y|Ys]) -> [{X,Y}|zip(Xs,Ys)].
然而,如果你想要一個更寬鬆的壓縮函式,你可以決定在其中一個列表完成時就結束。在這種情況下,你因此會有兩種基本情況。
lenient_zip([],_) -> [];
lenient_zip(_,[]) -> [];
lenient_zip([X|Xs],[Y|Ys]) -> [{X,Y}|lenient_zip(Xs,Ys)].
請注意,無論我們的基本情況是什麼,函式的遞迴部分都保持不變。我建議你嘗試建立自己的尾遞迴版本的 zip/2 和 lenient_zip/2,以確保你完全了解如何建立尾遞迴函式:它們將會是大型應用程式的核心概念之一,在這些應用程式中,我們的主要迴圈將會以這種方式建立。
如果你想檢查你的答案,請查看我在 recursive.erl 中的實作,更準確地說是 tail_zip/2 和 tail_lenient_zip/3 函式。
注意: 此處看到的尾遞迴不會使記憶體增長,因為當虛擬機器看到一個函式在尾部位置(函式中要評估的最後一個表達式)呼叫自身時,它會消除當前的堆疊幀。這稱為尾呼叫最佳化 (Tail-call Optimisation, TCO),它是更通用的最佳化名稱最後呼叫最佳化 (Last Call Optimisation, LCO) 的特例。
每當函式體中要評估的最後一個表達式是另一個函式呼叫時,就會執行 LCO。當這種情況發生時,就像 TCO 一樣,Erlang VM 會避免儲存堆疊幀。因此,尾遞迴也可以在多個函式之間進行。舉例來說,函式鏈 a() -> b(). b() -> c(). c() -> a(). 將有效地建立一個不會耗盡記憶體的無限迴圈,因為 LCO 避免了堆疊溢位。這個原理,加上我們對累加器的使用,就是使尾遞迴有用的原因。
快,排序!
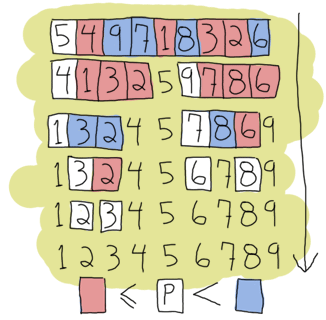
我現在可以(並且將會)假設你了解遞迴和尾遞迴的意義,但為了確保萬無一失,我將會推進到更複雜的例子,快速排序。是的,傳統的「嘿,看,我可以寫出簡短的函數式程式碼」的典型例子。快速排序的簡單實作方式是取列表的第一個元素,即樞紐,然後將所有小於或等於樞紐的元素放入一個新列表,並將所有較大的元素放入另一個列表。然後,我們對每個列表執行相同的操作,直到每個列表變得越來越小。這個過程會持續進行,直到你只剩下一個要排序的空列表,這將會是我們的基本情況。之所以說這種實作是簡單的,是因為更聰明的快速排序版本會嘗試選擇最佳的樞紐來加快速度。不過,我們在我們的範例中並不在意這一點。
我們需要兩個函式來實現這一點:第一個函式將列表分割成較小和較大的部分,第二個函式將分割函式應用於每個新列表並將它們黏合在一起。首先,我們將編寫黏合函式。
quicksort([]) -> [];
quicksort([Pivot|Rest]) ->
{Smaller, Larger} = partition(Pivot,Rest,[],[]),
quicksort(Smaller) ++ [Pivot] ++ quicksort(Larger).
這顯示了基本情況,一個由另一個函式分割成較大和較小部分的列表,使用一個樞紐,並將快速排序後的兩個列表附加在其前後。因此,這應該會處理組裝列表的工作。現在是分割函式。
partition(_,[], Smaller, Larger) -> {Smaller, Larger};
partition(Pivot, [H|T], Smaller, Larger) ->
if H =< Pivot -> partition(Pivot, T, [H|Smaller], Larger);
H > Pivot -> partition(Pivot, T, Smaller, [H|Larger])
end.
你現在可以執行你的快速排序函式了。如果你以前在網路上搜尋過 Erlang 的範例,你可能看過另一個快速排序的實作方式,它更簡單且更容易閱讀,但使用了列表推導式。易於替換的部分是那些建立新列表的部分,也就是 partition/4 函式。
lc_quicksort([]) -> [];
lc_quicksort([Pivot|Rest]) ->
lc_quicksort([Smaller || Smaller <- Rest, Smaller =< Pivot])
++ [Pivot] ++
lc_quicksort([Larger || Larger <- Rest, Larger > Pivot]).
主要的差異在於,這個版本更容易閱讀,但作為交換,它必須遍歷列表兩次才能將其分割成兩個部分。這是清晰度與效能之間的戰鬥,但真正的輸家是你,因為已經存在一個函式 lists:sort/1。請改用該函式。
不要喝太多 Kool-Aid
所有這些簡潔性對於教育目的來說是好的,但對於效能來說則不然。許多函數式程式設計教學永遠不會提及這一點!首先,這裡的兩種實作都需要多次處理與樞紐相等的值。我們可以決定改為返回 3 個列表:小於、大於和等於樞紐的元素,以提高效率。
另一個問題與我們在將所有分割後的列表附加到樞紐時,需要多次遍歷它們的方式有關。可以藉由在將列表分割成三個部分時進行串連來稍微減少開銷。如果你對此感到好奇,請查看 recursive.erl 的最後一個函式(bestest_qsort/1)以取得範例。
所有這些快速排序的一個好處是,它們將適用於你擁有的任何資料類型列表,甚至包括列表元組等等。試試看,它們都有效!
不只是列表
在閱讀本章之後,你可能會開始認為 Erlang 中的遞迴主要與列表有關。雖然列表是可以遞迴定義的資料結構的好例子,但當然不僅僅如此。為了多樣性,我們將了解如何建立二元樹,然後從中讀取資料。

首先,定義什麼是樹是很重要的。在我們的例子中,它是從上到下的節點。節點是包含一個鍵、一個與該鍵關聯的值,然後是另外兩個節點的元組。在這兩個節點中,我們需要一個鍵比包含它們的節點小的節點,以及一個鍵比包含它們的節點大的節點。這就是遞迴!一棵樹是一個包含節點的節點,每個節點又包含節點,而節點本身也包含節點。這不可能永遠持續下去(我們沒有無限的資料可以儲存),所以我們會說我們的節點也可以包含空節點。
為了表示節點,元組是一種合適的資料結構。對於我們的實作,我們可以將這些元組定義為 {node, {Key, Value, Smaller, Larger}}(一個標記的元組!),其中 Smaller 和 Larger 可以是另一個類似的節點或一個空節點({node, nil})。我們實際上不需要比這更複雜的概念。
讓我們開始為我們的 非常基本的樹實作建立一個模組。第一個函式 empty/0 返回一個空節點。空節點是新樹的起點,也稱為根。
-module(tree).
-export([empty/0, insert/3, lookup/2]).
empty() -> {node, 'nil'}.
藉由使用該函式,然後以相同的方式封裝所有節點的表示形式,我們隱藏了樹的實作,因此人們不需要知道它是如何建立的。所有這些資訊都可以僅由模組本身包含。如果你決定變更節點的表示形式,你可以在不破壞外部程式碼的情況下進行變更。
要將內容新增到樹中,我們必須首先了解如何在其中遞迴地導覽。讓我們以與其他每個遞迴範例相同的方式進行,嘗試找到基本情況。由於空樹是一個空節點,因此我們的基本情況在邏輯上就是一個空節點。因此,每當我們遇到一個空節點時,我們就可以在那裡新增我們的新鍵/值。在其他時間,我們的程式碼必須遍歷樹,嘗試找到一個可以放置內容的空節點。
若要從根節點開始尋找空節點,我們必須利用 Smaller 和 Larger 節點的存在,讓我們可以藉由將要插入的新鍵與目前節點的鍵進行比較來導覽。如果新鍵小於目前節點的鍵,我們嘗試在 Smaller 內部尋找空節點,如果它較大,則在 Larger 內部尋找。但是,還有最後一種情況:如果新鍵等於目前節點的鍵怎麼辦?我們在這裡有兩個選項:讓程式失敗或將值替換為新值。這是我們在這裡將採取的選項。將所有這些邏輯放入函式中,運作方式如下。
insert(Key, Val, {node, 'nil'}) ->
{node, {Key, Val, {node, 'nil'}, {node, 'nil'}}};
insert(NewKey, NewVal, {node, {Key, Val, Smaller, Larger}}) when NewKey < Key ->
{node, {Key, Val, insert(NewKey, NewVal, Smaller), Larger}};
insert(NewKey, NewVal, {node, {Key, Val, Smaller, Larger}}) when NewKey > Key ->
{node, {Key, Val, Smaller, insert(NewKey, NewVal, Larger)}};
insert(Key, Val, {node, {Key, _, Smaller, Larger}}) ->
{node, {Key, Val, Smaller, Larger}}.
請注意,此處的函式會傳回一棵全新的樹。這是僅具有單一分配的函數式語言的典型特徵。雖然這可能被認為是效率低下,但樹的兩個版本的大多數底層結構有時恰好是相同的,因此會被共享,僅在需要時由 VM 複製。
在這個範例樹狀結構實作中,剩下要做的就是建立一個 lookup/2 函式,讓你可以透過給定的鍵值在樹中找到值。所需的邏輯與將新內容新增到樹中的邏輯極為相似:我們逐步檢查節點,檢查查找的鍵值是否等於、小於或大於目前節點的鍵值。我們有兩個基本情況:一個是當節點為空時(鍵值不在樹中),另一個是當找到鍵值時。由於我們不希望程式每次查找不存在的鍵值時都崩潰,我們將返回原子 'undefined'。否則,我們將返回 {ok, Value}。這樣做的原因是,如果我們只返回 Value 並且節點包含原子 'undefined',我們將無法知道樹是否返回了正確的值還是未能找到它。透過將成功的情況包裝在這樣的元組中,我們可以很容易地理解哪個是哪個。以下是已實作的函式
lookup(_, {node, 'nil'}) ->
undefined;
lookup(Key, {node, {Key, Val, _, _}}) ->
{ok, Val};
lookup(Key, {node, {NodeKey, _, Smaller, _}}) when Key < NodeKey ->
lookup(Key, Smaller);
lookup(Key, {node, {_, _, _, Larger}}) ->
lookup(Key, Larger).
這樣我們就完成了。讓我們透過建立一個小型的電子郵件地址簿來測試它。編譯該檔案並啟動 shell
1> T1 = tree:insert("Jim Woodland", "jim.woodland@gmail.com", tree:empty()).
{node,{"Jim Woodland","jim.woodland@gmail.com",
{node,nil},
{node,nil}}}
2> T2 = tree:insert("Mark Anderson", "i.am.a@hotmail.com", T1).
{node,{"Jim Woodland","jim.woodland@gmail.com",
{node,nil},
{node,{"Mark Anderson","i.am.a@hotmail.com",
{node,nil},
{node,nil}}}}}
3> Addresses = tree:insert("Anita Bath", "abath@someuni.edu", tree:insert("Kevin Robert", "myfairy@yahoo.com", tree:insert("Wilson Longbrow", "longwil@gmail.com", T2))).
{node,{"Jim Woodland","jim.woodland@gmail.com",
{node,{"Anita Bath","abath@someuni.edu",
{node,nil},
{node,nil}}},
{node,{"Mark Anderson","i.am.a@hotmail.com",
{node,{"Kevin Robert","myfairy@yahoo.com",
{node,nil},
{node,nil}}},
{node,{"Wilson Longbrow","longwil@gmail.com",
{node,nil},
{node,nil}}}}}}}
現在你可以用它來查找電子郵件地址了
4> tree:lookup("Anita Bath", Addresses).
{ok, "abath@someuni.edu"}
5> tree:lookup("Jacques Requin", Addresses).
undefined
這就結束了我們用遞迴資料結構(而非列表)建立的功能性地址簿範例!安妮塔·巴斯現在...
注意: 我們的樹狀結構實作非常簡單:我們不支援常見的操作,例如刪除節點或重新平衡樹狀結構以加快後續的查找速度。如果你有興趣實作和/或探索這些操作,研究 Erlang 的 gb_trees 模組 (otp_src_R<version>B<revision>/lib/stdlib/src/gb_trees.erl) 的實作是一個好主意。這也是你在程式碼中處理樹狀結構時應該使用的模組,而不是重新發明你自己的輪子。
遞迴思考
如果你已經理解了本章中的所有內容,那麼遞迴思考可能會變得更加直觀。遞迴定義與其命令式對應物(通常在 while 或 for 迴圈中)相比,一個不同的方面是,我們的方法不是採取逐步的方法(「先做這個,然後做那個,然後做這個,然後就完成了」),而是更具宣告性(「如果你得到這個輸入,就做那個,否則就做這個」)。這種特性在函式標頭中使用模式匹配時會更加明顯。
如果你仍然不了解遞迴是如何運作的,也許閱讀這個會對你有幫助。
開玩笑的,遞迴與模式匹配相結合有時是撰寫簡潔且易於理解的演算法的最佳解決方案。透過將問題的每個部分細分為單獨的函式,直到它們無法再簡化為止,該演算法就變成了組裝一堆來自簡短常式的正確答案(這有點類似於我們對快速排序所做的事情)。這種心智抽象也可以透過你日常使用的迴圈來實現,但我認為使用遞迴更容易練習。你的情況可能有所不同。
現在,女士們先生們,來一場討論:作者與他自己的對話
- — 好吧,我想我了解遞迴了。我了解它的宣告性。我知道它有數學根源,就像不可變的變數一樣。我知道你在某些情況下覺得它更容易。還有什麼嗎?
- — 它遵循一個規則的模式。找到基本情況,把它們寫下來,然後其他所有情況都應該嘗試收斂到這些基本情況,以獲得你的答案。這使得撰寫函式變得相當容易。
- — 是的,我明白了,你已經重複了很多次了。我的迴圈也可以做同樣的事情。
- — 是的,它們可以。無法否認這一點!
- — 對。我不明白的是,如果它們不如尾遞迴版本好,你為什麼還要費心寫所有這些非尾遞迴的版本。
- — 哦,這只是為了讓事情更容易理解。從常規遞迴(更漂亮且更容易理解)轉移到理論上更有效率的尾遞迴,聽起來像是展示所有選項的好方法。
- — 好吧,所以它們除了教育用途之外都沒用,我明白了。
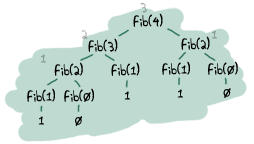
- — 不完全是這樣。實際上,你會看到尾遞迴和常規遞迴呼叫之間的效能差異很小。需要注意的區域是那些應該無限循環的函式,例如主迴圈。還有一種函式總是會產生非常大的堆疊,速度會很慢,如果沒有將它們設為尾遞迴,可能會很早崩潰。這方面最好的例子是費波那契函式,如果它不是迭代的或尾遞迴的,它會以指數級增長。
 你應該對你的程式碼進行分析(我保證會在稍後的章節中說明如何進行分析),看看是什麼減慢了速度,然後解決它。
你應該對你的程式碼進行分析(我保證會在稍後的章節中說明如何進行分析),看看是什麼減慢了速度,然後解決它。 - — 但迴圈總是迭代的,這就不是問題了。
- — 是的,但是... 但是... 我美麗的 Erlang...
- — 好吧,這不是很好嗎?所有這些學習都是因為 Erlang 中沒有 'while' 或 'for'。非常感謝你,我要回去用 C 語言編寫我的烤麵包機了!
- — 別那麼快!函數式程式設計語言還有其他優點!如果我們已經找到了一些基本情況模式來讓我們在撰寫遞迴函式時更輕鬆,那麼一群聰明的人也找到了更多,以至於你自己將需要撰寫的遞迴函式會非常少。如果你留下來,我會向你展示如何建構這樣的抽象。但是為此我們需要更多的力量。讓我來告訴你關於高階函式的事情...